
你有没有试过在没有说明书的情况下组装宜家家具?那种手忙脚乱却又充满期待的感觉,和设计大语言模型(LLM)系统时如出一辙。如果没有一个清晰的计划,很容易陷入混乱。我曾经也一头扎进去,满心期待却又手足无措,被网上那些复杂的架构图搞得晕头转向。于是,我坐下来,把它们都梳理了一遍。今天,我就把这份“梳理心得”分享给你,希望能帮你少走些弯路。
你将在这份指南中学到什么
这份指南可不只是教你把大语言模型简单地连到一个输入框,而是带你深入系统设计的思维,教你如何打造一个可扩展、能在生产环境中稳定运行的人工智能应用。接下来的内容,都是干货:
大语言模型系统究竟是什么?
核心组件有哪些?
如何部署与扩展?
带检索的生成(RAG)到底值不值得追?
如何设置保障措施、监控和防护网?
怎样从原型迈向生产?
大语言模型系统究竟是什么?
如果把大语言模型比作大脑,那么一个真正智能的系统就是一个完整的人。它不仅能思考,还能记住事情、做出决策、检查自己的工作,还能根据不同的场景灵活调整。要构建这样的系统,光有模型可不行,还得给它配上一套“黄金搭档”的支持系统。
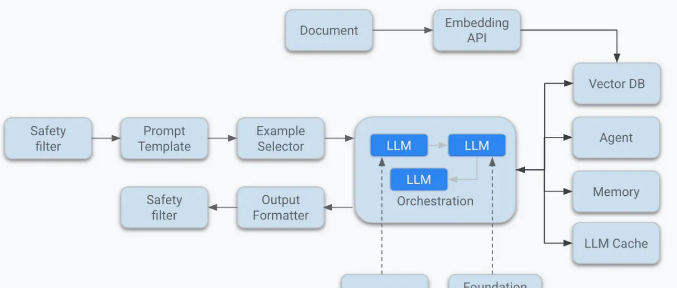
我们来逐一剖析这些“黄金搭档”:
检索器(Retrievers):大语言模型虽然知识渊博,但它可不是搜索引擎,没法实时获取最新的信息。这时候,检索器就派上用场了。它能通过语义搜索(通常借助 Pinecone、Weaviate、FAISS 或 Qdrant 这样的向量数据库)从你的文档、知识库、维基百科、数据库或 API 中找到最相关的资料,然后把这些资料注入到提示词里,再一起送给大语言模型。就好比给模型配了个“小助手”,在模型回答问题之前,先帮它把相关资料查一遍。
记忆模块(Memory modules):大多数大语言模型天生就是“健忘”的,它们默认不记得几分钟前发生的事。但用户可不希望跟一个“没记忆”的系统交流。他们期待系统能记住自己的名字、目标、之前的问题,甚至是对话中提到的内容。
记忆模块就有两种:
短期记忆:就像聊天时的“记忆窗口”,能记住最近几轮对话的内容,通常通过上下文窗口或缓存来管理。
长期记忆:则是把用户的一些持久性信息,比如偏好、历史对话等,存储在数据库里,或者把它们总结成向量嵌入,需要的时候再调出来。
评估器(Evaluators):大语言模型有时候会“自信过头”,即使输出的内容是错的、有害的,或者完全不搭边,它也毫不含糊地往外蹦。所以在生产环境中,我们不能完全信任它的输出。这时候,评估器就出场了。这些评估器可以是专门的子系统,比如另一个大语言模型或者分类器,它们的作用就是检查模型的输出是否符合我们的质量标准。
评估器可以在:
响应之前:过滤提示输入或者检索到的文档;
响应之后:对输出内容进行审核或者重新排序;
A/B 测试流程中:比较不同候选生成内容的好坏。
协调器(Orchestrators):大语言模型的本事可不少,总结、生成代码、搜索、规划、调用工具……样样都能来一手。可这么多功能,到底什么时候该用哪一个呢?这就得靠协调器来指挥了。它就像是人工智能交响乐团的“指挥家”,根据不同的场景和需求,决定模型在什么时候该做什么。
协调器可以用以下几种方式实现:
有限状态机:适用于简单的流程;
函数调用 API:比如 OpenAI 提供的工具调用功能;
规划代理:像 LangGraph 或 ReAct 这样的工具;
协调引擎:比如 LangChain、Haystack 或 Dust。
路由器(Routers):路由器就像是系统的“交通警察”,它会检查用户的输入,然后决定接下来该怎么走。
它的作用可不小:
优化延迟和成本:简单的问题用简单的模型处理,别浪费资源;
提高质量:遇到复杂问题,就调用更强大的模型;
避免失败:如果一个模型或工具出问题了,就切换到备用方案。
有了路由器,每个用户的问题都能找到最适合的处理方式,就像急诊室的护士根据病情决定你该看哪位医生一样。
监控工具(Monitoring tools):想象一下,如果你部署了一个有成千上万用户的大语言模型系统,却完全不知道它是不是在胡说八道、有没有出错,或者性能怎么样,那得多让人揪心啊!所以,监控可不是可有可无的。监控可以是手动的,比如查看日志、仪表盘,但现在很多团队都会用专业的可观测性平台,像 Langfuse、Helicone、TruLens、Phoenix,还有 OpenAI 自己的使用仪表盘,这些工具能帮你实时掌握系统的运行情况。
大语言模型的核心组件
大语言模型是任何AI系统应用的大脑,但要让它真正发挥出强大的作用,变成一个有用、可靠的产品,还得靠精心设计的系统来“保驾护航”。
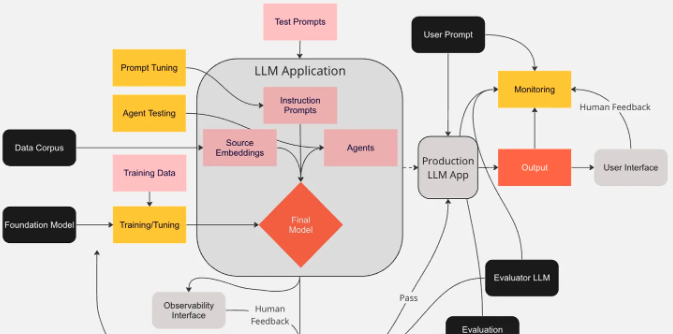
接下来,我们就来看看那些能把普通大语言模型变成强大、结构化、生产就绪系统的核心组件。
大语言模型(The LLM):整个系统的核心就是模型本身。你可以把它想象成一个超级智能的文本预测器。它并不知道具体的事实,但它能通过学习数据中的模式,根据你给它的提示词,预测出下一个最有可能出现的标记。在选择模型的时候,有几件事得好好考虑一下:
架构类型:是用只有解码器的结构,还是编码器 – 解码器的结构?
上下文长度:模型能处理多长的上下文?是 4k 标记,还是 128k 标记?
延迟、成本和微调能力:模型的响应速度怎么样?使用成本高不高?能不能根据你的需求进行微调
提示层(Prompting layer)
:提示词可不是随便写写的,它是你用来引导模型行为的关键“指令”。现在的提示层早就不是简单的人工输入了,而是用上了智能模板、动态指令生成和少量示例这些“黑科技”。它能把用户的问题、工具、文档、记忆和目标等内容,都整合成一个结构化的格式,让模型能够轻松理解。提示层主要包括:
系统提示:用来控制模型的语气和行为;
用户输入注入:把用户的问题加入到提示词中;
检索到的文档包含:把通过 RAG 检索到的相关文档也加进去。
检索器(Retriever):你的大语言模型几个月前就训练好了,它怎么可能知道你公司最新的政策,或者昨天的新闻呢?这就得靠检索器来帮忙了。它的原理是这样的:
先把文本分成小块,然后用编码器(比如 text-embedding-ada-002)把它们转换成向量嵌入;
把这些嵌入存储到向量数据库里,比如 FAISS、Weaviate 或 Pinecone;
当用户提问的时候,系统就从数据库里找出和问题语义最相似的那些文本块;
把这些相关的文本块加到提示词里,再一起送给模型。
这样一来,模型就能根据最新的信息来回答问题了。
记忆与状态(Memory & state):虽然检索器能帮模型获取最新的信息,但记忆模块的作用也不可小觑。它能让系统记住之前的对话内容,让用户感受到一种连续性。比如,系统可以这样说:“咱们之前不是聊过……”这样一来,就能让用户觉得这个系统很贴心,很有“人情味”。记忆模块主要有三种:
短期记忆:就像聊天时的记忆窗口,能记住最近几轮对话的内容;
长期记忆:把用户的偏好、历史对话等持久性信息存储在数据库里,或者把它们总结成向量嵌入;
结构化记忆:把用户的状态以键值对的形式存储在数据库里。
工具使用与函数调用(Tool use & Function calling):如果一个大语言模型只能生成文本,那它就跟只会说很多话但不采取行动的助手没什么两样。工具使用功能就能让模型“动起来”,比如运行计算、调用 API、搜索网络、查询数据库等等。具体来说,它是这样工作的:
模型收到一个提示词,里面描述了它可以使用的函数或工具;
模型根据提示词,输出一个结构化的 JSON 调用指令,比如 {“function_name”: “搜索”, “arguments”: {“关键词”: “人工智能”}};
后端系统收到指令后,调用相应的工具,把结果再反馈给模型。
这样一来,模型就能根据需要调用各种工具,完成更复杂的任务了。
部署与扩展——让大语言模型系统焕发生机
你的大语言模型系统搭建好了,可光让它跑起来还不够。你还得把它放到合适的地方,让它能应对真实世界的各种情况,而且随着需求的增长,还能灵活扩展。部署和扩展,就像是让想法落地生根,也是很多大语言模型项目从原型走向生产就绪的关键一步。
部署:
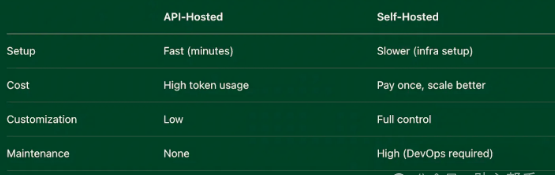
云 API 与自托管:托管模型主要有两条路可走。一是直接用现成的云 API,比如 OpenAI 或 Claude 提供的服务。这种方式特别简单,你只需要调用一个接口,就能得到响应,完全不用操心服务器的事,也没有复杂的运维工作。这是快速推出产品的最佳选择。但缺点也很明显,你得接受它们的定价策略、速率限制,而且对模型的具体运行情况也是一头雾水。
另一种方式就是自托管,自己搭建基础设施来运行开源模型,比如 LLaMA 或 Mistral。这种方式虽然前期投入大,但好处也很多。你可以根据自己的需求对模型进行微调,还能优化延迟,确保数据隐私,长期来看还能降低成本。不过,这也意味着你要承担起运维的重任,比如配置 GPU、搭建推理服务器(比如 vLLM 或 TGI),还要搞定负载均衡和系统的稳定性。
如果你还在快速迭代阶段,或者只想做一个最小可行产品(MVP),那用云 API 托管绝对是又快又方便的选择;
如果你对控制权、成本或者定制化有更高的要求,那自托管就是更好的选择。
扩展:
扩展可不仅仅是多处理几个用户那么简单,关键是要高效地应对更多用户的需求。一个性能出色的大语言模型系统,既要技术上能扛得住,又要经济上划算。冷启动是自托管系统的一大难题,有些模型加载到内存里就得花好几秒钟,这可太耽误事了。好在有些工具,比如 vLLM,能优化这个问题,让模型权重保持“热身”状态,同时还能高效管理 GPU 内存。
并发处理也是个大问题。应付一个用户很简单,但要是同时面对成千上万的用户,那可就麻烦了。这时候,异步 API、消息队列(比如 Kafka)和负载均衡器就派上用场了,它们能帮你稳住阵脚,避免系统在压力下崩溃。
还有内存管理,这也是个让人头疼的问题。要是提示词太长、对话太长,或者批量处理的数据太大,即使是性能再好的 GPU 也可能会被“撑爆”。所以,你得优化提示词的长度,把不相关的上下文内容去掉,或者干脆用更小的模型版本来运行。
流式传输也很重要,它能大大提升用户体验。与其让用户干等五秒钟才看到完整的回答,不如一边生成一边传输,让用户能实时看到内容。这可以通过服务器发送事件或 WebSockets 来实现,尤其适合聊天机器人这种界面。
检索增强生成(RAG)——真的值得追吗?
绝对值得!RAG 可不是什么空洞的流行词。它的核心思想是把大语言模型和外部检索系统结合起来,这样一来,模型就不用把所有知识都“装在肚子里”,只要知道去哪里找答案就行。
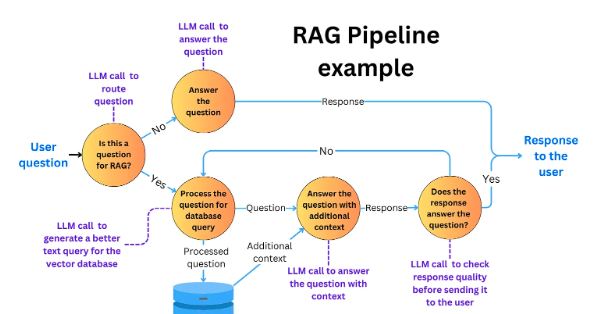
RAG 流程
检索:用户一提问,系统先从外部的知识库(比如向量存储)里把相关的文档找出来。
生成:大语言模型读了这些文档后,再生成一个更准确、更有根据的回答。
为什么它很重要?
减少胡言乱语:模型的回答不再是凭空想象,而是有真实可靠的来源作为支撑。
答案实时更新:你不用每次都重新训练模型,只要更新知识库里的内容就行。
成本更低:小一点、便宜一点的模型,也能通过这种方式表现得更好。
保障措施、监控与防护网
要是不加约束地把大语言模型放出去,那可太危险了,就好比在法律听证会上让一个即兴喜剧演员拿着麦克风乱说一通,肯定得乱套。所以,保障措施、监控和防护网就显得格外重要。这些可不是简单的“紧箍咒”,它们能让模型更可靠、更安全,也让使用者更放心。
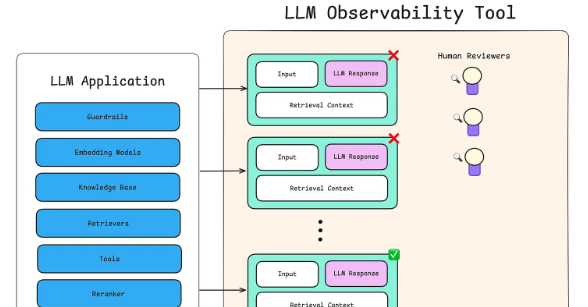
保障措施(Guardrails):
保障措施就好比是给模型设定的“交通规则”,防止它跑偏到危险、无关或者不合适的领域。这些规则可以是硬编码的逻辑,也可以是协调器执行的政策,甚至可以是专门的预处理或后处理过滤器。
示例:
阻止模型回答涉及敏感话题的内容,比如自杀、仇恨言论等;
不让模型给出医疗或法律建议。
监控(Monitoring):
监控就像是大语言模型系统的“黑匣子”,它能记录模型的行为,及时发现异常情况,并且把各种数据指标呈现出来,让开发人员心里有数。通常会监控以下内容:
延迟时间、每条查询消耗的令牌数量以及成本;
标记出来的输出内容,比如那些冒犯性、无意义或者毫无帮助的回答;
模型调用的工具或 API。
这些监控数据可以和 Prometheus、OpenTelemetry 这样的工具集成,或者用专门针对大语言模型可观测性设计的仪表盘来展示。
防护网(Safety Nets):
即使有了保障措施和监控,模型也难免会出错。防护网的作用就是在模型“摔倒”的时候,把它接住,并且尽量让事情回到正轨。常见的防护策略有:
备用模型:如果主模型出问题或者响应太慢,就切换到备用模型或者直接用缓存的答案;
人工介入(Human-in-the-loop,HITL):在企业环境或者受监管的场景里,把一些复杂的查询交给人工审核员来处理;
响应验证:用分类器或者评估器自动检查模型的回答,如果置信度低或者有害,就直接拒绝。
从原型到生产
原型阶段总是让人兴奋不已。你快速搭建了一个聊天界面,接入了一些 OpenAI 的 API 调用,甚至可能还加了一些 JSON 模式。嘿,它居然能说话了!可这样的原型,一旦面对真实世界的复杂问题、严格的监管要求,以及用户对稳定性的高期待,就很容易“露馅”。
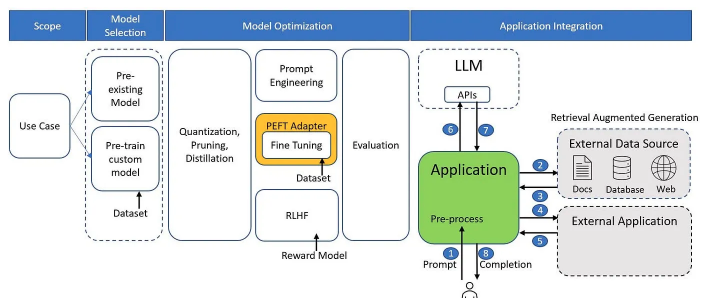
那么,到底要怎么做,才能把一个大语言模型系统从原型阶段,变成一个能 24/7 稳定运行、能应对大规模用户需求、在压力下也不会崩溃的生产级系统呢?
原型阶段:
这是你疯狂实验的阶段。你在这里测试各种提示词,换来换去地尝试不同的模型,大致勾勒出工作流程。这个阶段,速度才是最重要的。你通常会:
快速搭建一些简单的集成,比如用 Flask 应用、Streamlit 仪表盘或者 Jupyter 笔记本;
用手工挑选的示例来测试提示词和输出结果;
几乎不考虑版本控制或者测试。
说实话,这个阶段的系统很“脆弱”,没有监控、没有备用方案,甚至连边缘情况都顾不上考虑。但这也没关系,因为这是验证想法、收集用户反馈的阶段。
打下基础:
一旦你的原型开始受到关注,用户反馈越来越多,需求也越来越复杂,你就得开始转变思路了。不能再靠手动修复或者现场改提示词了,你需要一个更“靠谱”的系统。
这个阶段,你得像对待一个要在真实世界里长期运行的系统一样去构建它。引入模型和提示词的版本控制,为逻辑流程编写测试代码,用 CI/CD 流水线来安全地更新系统。日志和遥测数据成了你的眼睛,让你能在黑暗中看清模型的行为、发现它的弱点以及评估性能。
生产阶段:
生产阶段,系统得从“能用”变成“无论遇到什么情况都能用”。这不仅仅是关注输出质量的问题了,而是要全方位地考虑正常运行时间、延迟、监控、安全性以及可扩展性。模型可能会出错,API 可能会失败,用户的需求可能会突然暴增,你的系统都得扛得住。在这个阶段,你会面临以下挑战:
后端和模型端点的负载均衡以及自动扩展;
用于过滤不安全或无帮助输出的保障措施;
监控仪表盘,实时追踪延迟、成本、使用情况和错误;
处理 API 超时或模型失败的备用方案和重试机制;
安全访问控制和速率限制,防止滥用并符合相关法规。
持续反馈与迭代:
系统上线并不代表任务结束,这只是个新的开始。接下来,你要把精力放在提升性能、优化延迟和成本,以及根据真实用户的反馈进行优化上。提示词版本控制、动态模型路由和用户反馈记录等工具,都能帮你更智能地进行迭代。
最后感想:系统胜于脚本
用大语言模型构建应用,可不是简单地写几个巧妙的提示词,或者选一个“最好”的模型。关键是要构建一个有弹性、模块化、能适应现实世界复杂情况的系统。
从定义系统的核心组件,到用合适的基础设施进行扩展,嵌入检索以提升相关性,设置安全保障,再到从简陋的原型过渡到生产级部署,每一个环节都至关重要。你做的每一个决策,从协调器到可观测性,都决定了这个大语言模型是只能说几句漂亮话,还是真的能发挥出强大的作用。
最终,出色的大语言模型应用并不是靠孤立的组件拼凑出来的,而是源于深思熟虑的系统设计。如果你把系统当作一个整体来构建,而不是零散的脚本,它不仅会工作得很好,而且会经得起时间的考验。






















暂无评论内容