
概述
机器学习是一种人工智能技术,使计算机能够通过经验自动改进性能,主要分为监督学习(使用带标签的数据进行训练)、无监督学习(寻找无标签数据中的模式)、半监督学习(结合带标签和无标签数据)和强化学习(通过与环境交互学习)。它广泛应用于金融(信用评分)、医疗(疾病预测)、自动驾驶(路径规划)和自然语言处理(机器翻译)等领域,关键概念包括特征、模型、过拟合和交叉验证。本文我们使用ydf方法进行分别介绍。
pip install ydf -U分类(classification)
分类是预测有限可能值集合中的分类值(如枚举、类型或类)的任务。例如,从可能的颜色集合(红色、蓝色、绿色)中预测颜色是一个分类任务。分类模型的输出是可能类别的概率分布。预测的类别是概率最高的类别。当只有两个类别时,我们称之为二元分类。在这种情况下,模型只返回一个概率。分类标签可以是字符串、整数或布尔值。
训练分类模型
模型的任务(例如,分类、回归)由 task 学习者参数确定。此参数的默认值为 ydf.Task.CLASSIFICATION ,这意味着默认情况下,YDF 训练分类模型。
# 导入必要的库
import ydf # 导入 Yggdrasil 决策森林库
import pandas as pd # 导入 Pandas 库,用于加载小型数据集
# 下载分类数据集并将其加载为 Pandas DataFrame
ds_path = "https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset" # 数据集的路径
train_ds = pd.read_csv(f"{ds_path}/adult_train.csv") # 读取训练数据集
test_ds = pd.read_csv(f"{ds_path}/adult_test.csv") # 读取测试数据集
# 打印前5个训练样本
train_ds.head(5) # 显示训练数据集的前5行
#代码注释
#导入库:首先导入了 ydf 库(用于决策森林模型)和 pandas 库(用于数据处理)。
#下载数据集:指定了数据集的路径,并使用 pd.read_csv 方法从该路径下载并加载训练和测试数据集。
#显示数据:最后,使用 head(5) 方法显示训练数据集中前五个样本,以便快速查看数据的结构和内容。打印的结果
| age 年龄 | workclass 工作类别 | fnlwgt | education 教育 | education_num 教育程度 | marital_status 婚姻状况 | occupation 职业 | relationship 关系 | race 比赛 | sex 性别 | capital_gain 资本利得 | capital_loss 资本损失 | hours_per_week 每周小时数 | native_country 国籍 | income 收入 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44 | Private 私人 | 228057 | 7th-8th 7-8 月 | 4 | Married-civ-spouse 已婚-公民配偶 | Machine-op-inspct 机械操作检查员 | Wife 妻子 | White 白色 | Female 女性 | 0 | 0 | 40 | Dominican-Republic 多米尼加共和国 | <=50K ≤50K |
| 1 | 20 | Private 私人 | 299047 | Some-college 一些大学 | 10 | Never-married 从未结婚 | Other-service 其他服务 | Not-in-family 非家族成员 | White 白色 | Female 女性 | 0 | 0 | 20 | United-States 美国 | <=50K ≤50K |
| 2 | 40 | Private 私人 | 342164 | HS-grad 高中毕业生 | 9 | Separated 分离的 | Adm-clerical 行政文员 | Unmarried 未婚 | White 白色 | Female 女性 | 0 | 0 | 37 | United-States 美国 | <=50K ≤50K |
| 3 | 30 | Private 私人 | 361742 | Some-college 大专 | 10 | Married-civ-spouse 已婚,民用配偶 | Exec-managerial 执行经理 | Husband 丈夫 | White 白色 | Male 男 | 0 | 0 | 50 | United-States 美国 | <=50K ≤50K |
| 4 | 67 | Self-emp-inc 自我激励-公司 | 171564 | HS-grad 高中毕业 | 9 | Married-civ-spouse 已婚-民事配偶 | Prof-specialty 专业特长 | Wife 妻子 | White 白色 | Female 女性 | 20051 | 0 | 30 | England 英格兰 | >50K |
# 标签列是
train_ds["income"] 22792 rows × 1 columns
22792 行 × 1 列
可以训练一个分类模型:
创建模型:使用 ydf.RandomForestLearner 创建一个随机森林学习器。
label="income":指定要预测的目标标签为 “income”,即数据集中与收入相关的列。
task=ydf.Task.CLASSIFICATION:指定任务类型为分类(这是默认值,因此可以省略)。
训练模型:调用 .train(train_ds) 方法,使用之前加载的训练数据集 train_ds 来训练模型。训练完成后,模型将被保存在变量 model 中。
# 注意:ydf.Task.CLASSIFICATION 是 "task" 的默认值
model = ydf.RandomForestLearner(label="income", # 指定目标标签为 "income"
task=ydf.Task.CLASSIFICATION).train(train_ds) # 创建随机森林学习器并训练模型
evaluation = model.evaluate(test_ds)
evaluation
#评估指标可以直接在评估对象中访问。
print(evaluation.accuracy)
#精度:0.8657999795270754Train model on 22792 examples Model trained in 0:00:01.808830
分类模型使用准确率、混淆矩阵、ROC-AUC 和 PR-AUC 进行评估。您可以使用 ROC 和 PR 图进行丰富的评估。
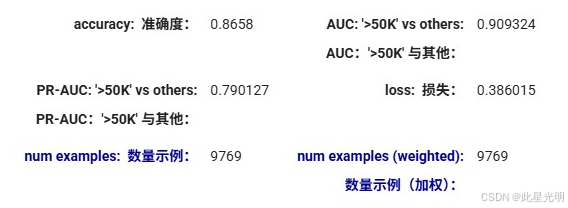
Confusion matrix 混淆矩阵
| Label Pred 标签 预测 | <=50K ≤50K | >50K >50K |
|---|---|---|
| <=50K ≤50K | 6962 | 861 |
| >50K >50K | 450 | 1496 |
分类模型评估
Accuracy 准确率
最简单的指标。它是预测正确的百分比(与真实值匹配)。
例子:如果一个模型正确地将 90 张图像识别为猫或狗,准确率为 90%。
Confusion Matrix 混淆矩阵
一个显示以下计数情况的表格:
True Positives (TP): Model correctly predicted positive.
真阳性(TP):模型正确预测为阳性。
True Negatives (TN): Model correctly predicted negative.
真阴性(TN):模型正确预测为阴性。
False Positives (FP): Model incorrectly predicted positive (a “false alarm”).
假阳性(FP):模型错误地预测为阳性(“误报”)。
False Negatives (FN): Model incorrectly predicted negative (a “miss”).
假阴性(FN):模型错误地预测为负(一个“漏网之鱼”)。
Threshold 阈值
YDF 分类模型为每个类别预测一个概率。阈值决定了将某事物分类为阳性或阴性的截止点。
例子:如果阈值是 0.5,任何高于 0.5 的预测可能会被分类为“垃圾邮件”,任何低于的则被分类为“非垃圾邮件”。
ROC Curve (Receiver Operating Characteristic Curve)
受试者工作特征曲线(ROC 曲线)
在各种阈值下,绘制真实正例率(TPR)与假正例率(FPR)的图表。
TPR (Sensitivity or Recall): TP / (TP + FN) – How many of the actual positives did the model catch?
TPR(灵敏度或召回率):TP / (TP + FN) – 模型捕捉了多少实际正例?
FPR: FP / (FP + TN) – How many negatives were incorrectly classified as positives?
FPR:FP / (FP + TN) – 有多少负例被错误地分类为正例?
解释:一个好的模型具有紧贴右上角的 ROC 曲线(高 TPR,低 FPR)。
AUC (Area Under the ROC Curve)
AUC(ROC 曲线下的面积)
一个总结 ROC 曲线整体表现的单一数值。AUC 比准确率更稳定。多分类模型评估一个类别与其他所有类别。
解释:范围从 0 到 1。完美模型的 AUC 为 1,而随机模型的 AUC 为 0.5。越高越好。
Precision-Recall Curve 精确率-召回率曲线
在各种阈值下,绘制精确率与召回率关系的图表。
Precision: TP / (TP + FP) – Out of all the predictions the model labeled as positive, how many were actually positive?
精确率:TP / (TP + FP) – 在所有模型标记为正例的预测中,有多少实际上是正例?
Recall (same as TPR): TP / (TP + FN) – Out of all the actual positive cases, how many did the model correctly identify?
召回率(与 TPR 相同):TP / (TP + FN) – 在所有实际正例中,模型正确识别了多少?
解释:一个好的模型具有曲线保持较高的特点(高精确度和高召回率)。在处理不平衡数据集(例如,当一个类别远比另一个类别稀有时)时特别有用。
PR-AUC (Area Under the Precision-Recall Curve)
PR-AUC(精确率-召回率曲线下的面积)
与 AUC 类似,但针对精确率-召回率曲线。用一个数字总结性能。多类别分类模型评估一个类别与其他所有类别。数值越高越好。
Threshold / Accuracy Curve
阈值/准确率曲线
一张图表,展示了随着分类阈值的改变,模型准确率的变化情况。
Threshold / Volume Curve 阈值/体积曲线
一张图表,展示了随着阈值的改变,被分类为正例的数据点数量的变化。
进行预测
分类模型预测标签类别的概率。二元分类模型根据 model.label_classes() 输出第一个类别的概率。
打印标签类别:使用 model.label_classes() 方法,输出模型中定义的所有标签类别。这可以帮助了解模型将要预测的不同收入类别(如高收入和低收入)。
进行预测:使用 model.predict(test_ds) 方法,对测试数据集 test_ds 中的每个样本进行预测。此方法将返回每个样本属于各个类别的预测概率或类别标签。
# 打印标签类别
print(model.label_classes()) # 显示模型中定义的所有标签类别
# 预测第一个类别的概率
print(model.predict(test_ds)) # 使用测试数据集对每个样本进行预测,输出预测结果
['<=50K', '>50K'] [0.01333333 0.12999995 0.9499992 ... 0.06000001 0.02333334 0. ]
我们也可以直接预测最可能的类别。
警告:始终使用 model.predict_class() 或手动检查类别的顺序使用 model.label_classes() 。请注意,标签类别的顺序可能会根据训练数据集或 YDF 更新而改变。
model.predict_class(test_ds)
array(['<=50K', '<=50K', '>50K', ..., '<=50K', '<=50K', '<=50K'],
shape=(9769,), dtype='<U5')
回归(regression)
回归是预测数值的任务,例如计数、度量或数量。例如,预测动物的年龄或产品的成本都是回归问题。默认情况下,回归模型的输出是期望值,即最小化平方误差的值。回归标签可以是整数或浮点数。
训练回归模型
模型的任务(例如,分类、回归、排序、提升)由学习器参数 task 决定。
导入库:导入 ydf 库(用于决策森林模型)和 pandas 库(用于数据处理)。
下载数据集:指定数据集的路径,并使用 pd.read_csv 方法从该路径加载整个数据集(这里是“abalone”数据集)。
随机分割数据集:
all_ds.sample(frac=1):随机打乱整个数据集。
split_idx = len(all_ds) * 7 // 10:计算出分割索引,确定70%的数据用于训练。
train_ds = all_ds.iloc[:split_idx]:根据计算的索引获取训练数据集。
test_ds = all_ds.iloc[split_idx:]:获取剩余的30%数据作为测试数据集。
显示数据:使用 head(5) 方法显示训练数据集的前五个样本,以便快速查看数据的结构和内容。
# 导入必要的库
import ydf # 导入 Yggdrasil 决策森林库
import pandas as pd # 导入 Pandas 库,用于加载小型数据集
# 下载分类数据集并将其加载为 Pandas DataFrame
ds_path = "https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset" # 数据集的路径
all_ds = pd.read_csv(f"{ds_path}/abalone.csv") # 读取整个数据集
# 随机将数据集分为训练集(70%)和测试集(30%)
all_ds = all_ds.sample(frac=1) # 随机打乱数据集
split_idx = len(all_ds) * 7 // 10 # 计算分割索引,70%的数据用于训练
train_ds = all_ds.iloc[:split_idx] # 获取训练数据集
test_ds = all_ds.iloc[split_idx:] # 获取测试数据集
# 打印前5个训练样本
train_ds.head(5) # 显示训练数据集的前5行
| Type 类型 | LongestShell 最长壳 | Diameter 直径 | Height 高度 | WholeWeight 全重 | ShuckedWeight 去壳重 | VisceraWeight 内脏重 | ShellWeight 壳重 | Rings 环 | |
|---|---|---|---|---|---|---|---|---|---|
| 3191 | M | 0.650 | 0.515 | 0.180 | 1.3315 | 0.5665 | 0.3470 | 0.405 | 13 |
| 1752 | M | 0.710 | 0.560 | 0.220 | 2.0150 | 0.9215 | 0.4540 | 0.566 | 11 |
| 2238 | I | 0.460 | 0.335 | 0.110 | 0.4440 | 0.2250 | 0.0745 | 0.110 | 8 |
| 3 | M | 0.440 | 0.365 | 0.125 | 0.5160 | 0.2155 | 0.1140 | 0.155 | 10 |
| 2685 | M | 0.625 | 0.480 | 0.145 | 1.0850 | 0.4645 | 0.2445 | 0.327 | 10 |
train_ds["Rings"]
3191 13 1752 11 2238 8 3 10 2685 10 .. 1845 8 603 11 3264 12 1268 11 2104 11 Name: Rings, Length: 2923, dtype: int64
我们可以训练一个回归模型:
创建模型:使用 ydf.GradientBoostedTreesLearner 创建一个梯度提升树学习器。
label="Rings":指定要预测的目标标签为 “Rings”,通常表示与每个样本相关的环数(在“abalone”数据集中)。
task=ydf.Task.REGRESSION:指定任务类型为回归,表示模型将预测一个连续值。
训练模型:调用 .train(train_ds) 方法,使用之前加载的训练数据集 train_ds 来训练模型。训练完成后,模型将被保存在变量 model 中。
# 创建并训练一个梯度提升树模型
model = ydf.GradientBoostedTreesLearner(label="Rings", # 指定目标标签为 "Rings",即要预测的环数
task=ydf.Task.REGRESSION).train(train_ds) # 设置任务为回归,并使用训练数据集训练模型
Train model on 2923 examples Model trained in 0:00:00.590275
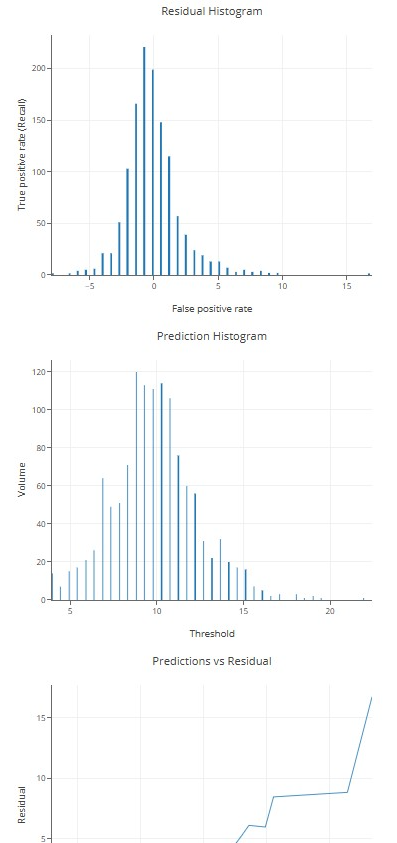
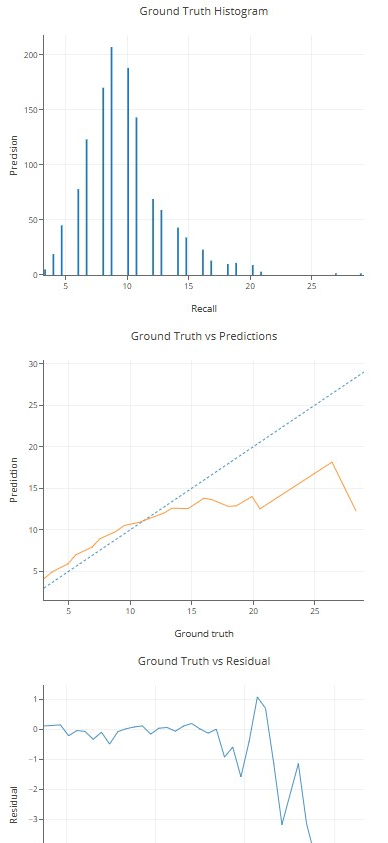
回归模型使用 RMSE(均方根误差)进行评估。
evaluation = model.evaluate(test_ds)
print(evaluation)
#你可以绘制包含更多图表的丰富评估。
evaluationRMSE: RMSE:
2.13062
num examples: 样本数量:
1254
num examples (weighted):数量示例(加权):
1254
排名(ranking)
排名,也称为学习排名,是指确定项目顺序的任务。例如,当你在谷歌上搜索查询时,它会排名网页并首先显示排名靠前的结果。表示排名数据集的一种常见方式是使用“相关性”分数。元素的顺序由其相关性定义:相关性更高的项目应排在相关性较低的项目之前。错误的成本由预测项目的相关性与正确项目的相关性之间的差异定义。例如,将相关性为 3 和 4 的两个项目错误排序,不如将相关性为 1 和 5 的两个项目错误排序严重。YDF 期望排名数据集以“扁平”格式呈现。一个查询和相应文档的数据集可能如下所示:
| query 查询 | document_id 文档 ID | feature_1 功能 1 | feature_2 功能 2 | relevance 相关性 |
|---|---|---|---|---|
| cat 猫 | 1 | 0.1 | blue 蓝色 | 4 |
| cat 猫 | 2 | 0.5 | green 绿色 | 1 |
| cat 猫 | 3 | 0.2 | red 红色 | 2 |
| dog 狗 | 4 | NA | red 红色 | 0 |
| dog 狗 | 5 | 0.2 | red 红色 | 0 |
| dog 狗 | 6 | 0.6 | green 绿色 | 1 |
相关性/标签是一个介于 0 到 5 之间的浮点数值(通常介于 0 到 4 之间),其中 0 表示“完全不相关”,4 表示“非常相关”,5 表示“与查询完全相同”。
在这个例子中,文档 1 与查询“猫”非常相关,而文档 2 仅与猫“相关”。没有关于“狗”的文档(文档 6 的相关性最高为 1)。然而,对于“狗”这个查询,仍然期望返回文档 6(因为这是谈论“狗”最多的文档)。
训练排名模型
模型的任务(例如,分类、回归、排名、提升)由学习器参数 task 确定。
导入库:导入了 ydf(用于决策森林模型)、pandas(用于数据处理)和 numpy(用于数值计算)库。
下载数据集:指定数据集的路径,并使用 pd.read_csv 方法从该路径加载训练和测试数据集(这里是合成排名数据集)。
显示数据:使用 head(5) 方法显示训练数据集的前五个样本,以便快速查看数据的结构和内容。
# 导入必要的库
import ydf # 导入 Yggdrasil 决策森林库
import pandas as pd # 导入 Pandas 库,用于加载小型数据集
import numpy as np # 导入 NumPy 库,用于数值计算
# 下载并加载排名数据集为 Pandas DataFrame
ds_path = "https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset" # 数据集的路径
train_ds = pd.read_csv(f"{ds_path}/synthetic_ranking_train.csv") # 读取训练数据集
test_ds = pd.read_csv(f"{ds_path}/synthetic_ranking_test.csv") # 读取测试数据集
# 打印前5个训练样本
train_ds.head(5) # 显示训练数据集的前5行
| GROUP | LABEL | cat_int_0 猫整数_0 | cat_int_1 猫整数_1 | cat_str_0 猫字符串_0 | cat_str_1 猫字符串_1 | num_0 | num_1 | num_2 | num_3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | G0 | 0.493644 | NaN | 11.0 | V_18 | V_7 | 0.923738 | 0.373921 | 0.154973 | 0.892344 |
| 1 | G0 | 1.461350 | 28.0 | 5.0 | V_15 | V_28 | 0.627094 | 0.907925 | 0.556397 | 0.839919 |
| 2 | G0 | 0.662606 | 6.0 | 22.0 | NaN | V_2 | 0.690948 | 0.129315 | 0.832686 | 0.318354 |
| 3 | G0 | 2.510630 | 7.0 | 1.0 | V_5 | V_12 | 0.698481 | NaN | 0.899466 | 0.831899 |
| 4 | G0 | 0.691813 | 15.0 | 24.0 | V_7 | V_27 | 0.102744 | 0.237528 | 0.379345 | 0.699236 |
在此数据集中,每一行代表一个查询/文档对(称为“GROUP”)。“LABEL”表示相关性,它表示查询与文档匹配的程度。查询和文档的特征合并为其他列中的特征,例如 cat_int_0 、 cat_int_1 等。
我们可以训练一个排序模型:
创建模型:使用 ydf.GradientBoostedTreesLearner 创建一个梯度提升树学习器,适用于排名任务。
label="LABEL":指定要预测的目标标签为 “LABEL”,表示需要进行排名的标签。
ranking_group="GROUP":指定用于排名的组标签为 “GROUP”,这通常用于定义在同一组内进行排名的样本。
task=ydf.Task.RANKING:指定任务类型为排名,表示模型将根据标签对样本进行排序。
训练模型:调用 .train(train_ds) 方法,使用之前加载的训练数据集 train_ds 来训练模型。训练完成后,模型将被保存在变量 model 中。
# 创建并训练一个梯度提升树模型,用于排名任务
model = ydf.GradientBoostedTreesLearner(
label="LABEL", # 指定目标标签为 "LABEL",即要预测的排名标签
ranking_group="GROUP", # 指定用于排名的组标签为 "GROUP"
task=ydf.Task.RANKING # 设置任务类型为排名
).train(train_ds) # 使用训练数据集训练模型
Train model on 3990 examples Model trained in 0:00:00.695050
默认情况下,YDF 使用 NDCG 评估排序模型。
评估模型:使用 model.evaluate(test_ds) 方法,对模型在测试数据集 test_ds 上的表现进行评估。评估结果通常包括模型的准确性、损失值或其他性能指标,具体取决于模型和任务类型。
输出结果:使用 print(evaluation) 将评估结果输出到控制台,以便查看模型的性能表现。
# 评估模型在测试数据集上的表现
evaluation = model.evaluate(test_ds) # 使用测试数据集对模型进行评估,并保存评估结果
# 打印评估结果
print(evaluation) # 输出评估结果
NDCG: 0.726741 num examples: 1010 num examples (weighted): 1010
uplifting(提升效果/提振)
提振建模是一种统计建模技术,用于预测对某一主题采取行动的增量影响。该行动通常被称为治疗,可能或可能不实施。
提振建模常用于定向营销活动,以预测个人在接收到营销展示后购买的可能性(或任何其他期望的行为)增加。
例如,提升建模可以预测电子邮件的效果。效果定义为条件概率 egin{align} ext{effect}( ext{email}) = &Pr( ext{outcome}= ext{purchase} vert ext{treatment}= ext{with email})\ &- Pr( ext{outcome}= ext{purchase} vert ext{treatment}= ext{no email}), end{align} 其中 $Pr( ext{outcome}= ext{purchase} vert …)$ 是根据是否收到电子邮件购买的概率。
与分类模型相比:使用分类模型,可以预测购买的几率。然而,高概率的客户可能会在商店消费,无论他们是否收到电子邮件。
同样,可以使用数值提升来预测收到电子邮件时的消费增加量。相比之下,回归模型只能增加预期消费,这在许多情况下是一个不那么有用的指标。
在 YDF 中定义提升模型
YDF 期望提升数据集以“扁平”flat””格式呈现。一个客户数据集可能看起来像这样
| treatment 处理 | outcome 结果 | feature_1 特征_1 | feature_2 |
|---|---|---|---|
| 0 | 1 | 0.1 | blue 蓝色 |
| 0 | 0 | 0.2 | blue 蓝色 |
| 1 | 1 | 0.3 | blue 蓝色 |
| 1 | 1 | 0.4 | blue 蓝色 |
处理是一个二元变量,表示示例是否接受了处理。在上面的示例中,处理表示客户是否收到了电子邮件。结果(标签)表示接受处理(或未接受处理)后的示例状态。TF-DF 支持分类提升中的分类结果和数值提升中的数值结果。
注意:提升法也常用于医疗领域。在这里,处理可以是医疗处理(例如,接种疫苗),标签可以是生活质量指标(例如,患者是否生病)。这也解释了提升建模的命名法。
训练提升模型
在本例中,我们将使用个性化治疗效果的模拟实例。
导入库:导入了 ydf(用于决策森林模型)、pandas(用于数据处理)和 numpy(用于数值计算)库。
下载数据集:指定数据集的路径,并使用 pd.read_csv 方法从该路径加载训练和测试数据集(这里是模拟 PTE 数据集)。
显示数据:使用 head(5) 方法显示训练数据集的前五个样本,以便快速查看数据的结构和内容。
# 导入必要的库
import ydf # 导入 Yggdrasil 决策森林库
import pandas as pd # 导入 Pandas 库,用于加载小型数据集
import numpy as np # 导入 NumPy 库,用于数值计算
# 下载并加载排名数据集为 Pandas DataFrame
ds_path = "https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset" # 数据集的路径
train_ds = pd.read_csv(f"{ds_path}/sim_pte_train.csv") # 读取训练数据集
test_ds = pd.read_csv(f"{ds_path}/sim_pte_test.csv") # 读取测试数据集
# 打印前5个样本
train_ds.head(5) # 显示训练数据集的前5行
| y | treat 治疗 | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | … | X11 | X12 | X13 | X14 | X15 | X16 | X17 | X18 | X19 | X20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2.027911 | 0.278222 | 0.716672 | -1.092175 | -1.353849 | -0.910061 | -1.410070 | -0.150630 | … | 1.931576 | 0.511000 | -1.618037 | -0.699228 | -0.494174 | 0.196550 | -0.150307 | -0.511604 | -0.995799 | -0.560476 |
| 1 | 2 | 2 | -1.494750 | -1.602538 | -0.283501 | -1.337542 | -0.579377 | 0.280663 | -1.721265 | 0.800941 | … | -0.616475 | 1.807993 | 0.379181 | 0.996452 | 1.127593 | 0.650113 | -0.327757 | 0.236938 | -1.039955 | -0.230177 |
| 2 | 1 | 2 | -1.572949 | -0.320900 | -1.135464 | 1.109242 | -0.861044 | -1.035670 | 0.665445 | -1.186718 | … | -0.562567 | -1.702615 | 1.902250 | -0.692745 | -1.146950 | 0.671004 | -1.448165 | -0.541589 | -0.017980 | 1.558708 |
| 3 | 1 | 2 | -0.300212 | -1.226114 | -0.632817 | 0.810701 | 0.972678 | 0.273049 | -0.430807 | 0.430636 | … | -0.989963 | 0.287449 | 0.601874 | -0.103483 | 1.481019 | -1.284158 | -0.697285 | 1.219228 | -0.132175 | 0.070508 |
| 4 | 1 | 1 | -0.764373 | -0.776658 | 1.351161 | -0.875981 | 0.619146 | 0.537798 | -0.329039 | 0.216747 | … | 2.731228 | -0.269114 | 1.732350 | 0.603866 | 0.916191 | -2.026110 | 2.598490 | 0.174136 | -2.549343 | 0.129288 |
5 rows × 22 columns
在这个数据集中,治疗( treat )和结果( y )是表示为“1”或“2”的二进制变量(而不是“0”和“1”)
我们可以训练一个提升模型:
创建模型:使用 ydf.RandomForestLearner 创建一个随机森林学习器,适用于分类提升任务。
label="y":指定要预测的目标标签为 “y”,表示模型将根据该标签进行分类。
uplift_treatment="treat":指定用于提升的处理标签为 “treat”,这通常用于区分实验组(接受处理)和对照组(未接受处理)。
task=ydf.Task.CATEGORICAL_UPLIFT:指定任务类型为分类提升,表示模型将评估处理对结果的影响。
训练模型:调用 .train(train_ds) 方法,使用之前加载的训练数据集 train_ds 来训练模型。训练完成后,模型将被保存在变量 model 中。
# 创建并训练一个随机森林模型,用于分类提升任务
model = ydf.RandomForestLearner(
label="y", # 指定目标标签为 "y",即要预测的分类标签
uplift_treatment="treat", # 指定提升处理标签为 "treat",用于区分处理组与对照组
task=ydf.Task.CATEGORICAL_UPLIFT # 设置任务类型为分类提升
).train(train_ds) # 使用训练数据集训练模型
Train model on 1000 examples Model trained in 0:00:00.075023
提升模型使用 QINI 系数(Qini 曲线下的面积)和 AUUC(提升曲线下的面积)进行评估。
evaluation = model.evaluate(test_ds)
print(evaluation)QINI: 0.106807 AUUC: 0.120807 num examples: 2000 num examples (weighted): 2000
异常检测(Anomaly detection)
pip install ydf ucimlrepo scikit-learn umap-learn plotly -U -q异常检测技术是非监督学习算法,用于识别数据中的稀有和异常模式,这些模式与正常模式有显著差异。例如,异常检测可用于欺诈检测、网络入侵检测和故障诊断,无需定义异常实例。
决策树异常检测是一种简单但有效的表格数据技术。模型为每个数据点分配一个异常分数,范围从 0(正常)到 1(异常)。决策树还提供了解释工具和属性,使得理解和描述检测到的异常更加容易。
在异常检测中,标记的示例不是用于训练,而是用于评估模型。这些标签确保模型可以检测已知的异常。
我们在 UCI Covertype 数据集上训练和评估了两种异常检测模型,该数据集描述了森林覆盖类型和土地单元的其他地理属性。第一个模型在松树和柳树数据上训练。鉴于柳树比松树稀少,该模型可以在没有标签的情况下区分它们。这个第一个模型然后将解释并描述构成松树覆盖类型的内容。
导入库:
ydf:用于构建和训练异常检测模型。
pandas:用于数据处理和加载数据集。
sklearn.metrics:用于计算模型性能指标,如 AUC。
ucimlrepo:用于下载 UCI 机器学习库中的数据集。
matplotlib.pyplot 和 seaborn:用于数据可视化。
umap:用于将高维数据降维到二维空间,以便可视化。
plotly:用于创建交互式图表,增强数据可视化体验。
设置 Plotly 渲染器:将 Plotly 的默认渲染器设置为 “colab”,以便在 Google Colab 环境中进行交互式绘图。
禁用 Pandas 警告:通过设置 pd.options.mode.chained_assignment 为 None,关闭链式赋值的警告,以减少不必要的警告信息。
# 导入必要的库
import ydf # 导入 Yggdrasil 决策森林库,用于学习异常检测模型
import pandas as pd # 导入 Pandas 库,用于加载小型数据集
from sklearn import metrics # 导入 sklearn 库,用于计算 AUC(曲线下面积)
from ucimlrepo import fetch_ucirepo # 导入 ucimlrepo 库,用于下载数据集
import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘图
import seaborn as sns # 导入 Seaborn 库,用于更美观的绘图
import umap # 导入 UMAP 库,用于将高维数据投影到二维空间
# 导入用于交互式绘图的库
import plotly.graph_objs as go # 导入 Plotly 的图形对象模块
from plotly.offline import iplot # 导入 Plotly 的离线绘图功能
import plotly.io as pio # 导入 Plotly 的输入输出模块
pio.renderers.default = "colab" # 设置 Plotly 的默认渲染器为 Colab
# 禁用 Pandas 警告
pd.options.mode.chained_assignment = None # 关闭链式赋值警告
/usr/local/google/home/gbm/my_venv/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm 2024-06-17 13:06:13.648825: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2024-06-17 13:06:14.292005: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
我们从 UCI 下载 Covertype 数据集。
准备数据集
下载数据集:
fetch_ucirepo(id=31):使用 fetch_ucirepo 函数从 UCI 机器学习库下载 ID 为 31 的覆盖类型数据集。该数据集用于分类和回归任务,包含关于森林覆盖类型的信息。
合并数据:
pd.concat([...], axis=1):使用 pd.concat 将特征数据和目标数据按列合并,创建一个完整的数据集 raw_dataset。axis=1 表示按列合并,使得特征和对应的目标标签在同一 DataFrame 中。
# 从 UCI 机器学习库下载覆盖类型数据集
covertype_repo = fetch_ucirepo(id=31) # 使用指定的 ID 下载数据集
# 合并特征和目标数据,创建完整的数据集
raw_dataset = pd.concat([covertype_repo.data.features, covertype_repo.data.targets], axis=1) # 将特征和目标数据按列合并
选择感兴趣的列并清理标签
复制数据集:
dataset = raw_dataset.copy():创建原始数据集的副本,以便在不修改原始数据的情况下进行处理。
选择特征:
定义一个特征列表 features,包括与森林覆盖类型相关的多个环境特征。
dataset = dataset[features + ["Cover_Type"]]:选择这些特征以及目标标签 “Cover_Type”,形成一个新的 DataFrame。
映射覆盖类型:
使用 map 方法将数值型的覆盖类型转换为对应的文本标签,使数据更易于理解。
显示数据:
dataset.head():显示处理后数据集的前五行,以便快速查看数据结构和内容。
# 创建数据集的副本
dataset = raw_dataset.copy() # 复制原始数据集,以便进行后续处理
# 选择感兴趣的特征
features = ["Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology",
"Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways",
"Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm",
"Horizontal_Distance_To_Fire_Points"] # 定义特征列表
dataset = dataset[features + ["Cover_Type"]] # 选择特征和目标标签(覆盖类型)
# 将覆盖类型映射为文本
dataset["Cover_Type"] = dataset["Cover_Type"].map({
1: "Spruce/Fir", # 将 1 映射为 "Spruce/Fir"
2: "Lodgepole Pine", # 将 2 映射为 "Lodgepole Pine"
3: "Ponderosa Pine", # 将 3 映射为 "Ponderosa Pine"
4: "Cottonwood/Willow", # 将 4 映射为 "Cottonwood/Willow"
5: "Aspen", # 将 5 映射为 "Aspen"
6: "Douglas-fir", # 将 6 映射为 "Douglas-fir"
7: "Krummholz" # 将 7 映射为 "Krummholz"
})
# 显示数据集的前几行
dataset.head() # 打印处理后的数据集的前5行
| Elevation 高程 | Aspect 坡向 | Slope 坡度 | Horizontal_Distance_To_Hydrology 水文距离(水平) |
Vertical_Distance_To_Hydrology 垂直距离至水文 |
Horizontal_Distance_To_Roadways 水平距离至道路 |
Hillshade_9am 阴影_上午 9 点 | Hillshade_Noon 中午阴影 | Hillshade_3pm 下午 3 点阴影 | Horizontal_Distance_To_Fire_Points 到火点的水平距离 |
Cover_Type 覆盖类型 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2596 | 51 | 3 | 258 | 0 | 510 | 221 | 232 | 148 | 6279 | Aspen 白杨 |
| 1 | 2590 | 56 | 2 | 212 | -6 | 390 | 220 | 235 | 151 | 6225 | Aspen 白杨 |
| 2 | 2804 | 139 | 9 | 268 | 65 | 3180 | 234 | 238 | 135 | 6121 | Lodgepole Pine 黄杉 |
| 3 | 2785 | 155 | 18 | 242 | 118 | 3090 | 238 | 238 | 122 | 6211 | Lodgepole Pine 黄杉 |
| 4 | 2595 | 45 | 2 | 153 | -1 | 391 | 220 | 234 | 150 | 6172 | Aspen 阿斯彭 |
第一个模型是在“过滤后的数据集”上训练的,该数据集仅包含云杉/冷杉和杨树/柳树示例。
过滤数据集:
dataset["Cover_Type"].isin(["Spruce/Fir", "Cottonwood/Willow"]):检查 “Cover_Type” 列中是否包含 “Spruce/Fir” 或 “Cottonwood/Willow”。isin 方法返回一个布尔系列,用于指示每一行是否满足条件。
filtered_dataset = dataset[...]:使用布尔索引从原始数据集中筛选出符合条件的行,创建一个新的 DataFrame filtered_dataset,仅包含覆盖类型为 “Spruce/Fir” 或 “Cottonwood/Willow” 的数据。
这样,filtered_dataset 只包含感兴趣的两种覆盖类型的数据,便于后续分析或建模。
# 过滤数据集,仅保留覆盖类型为 "Spruce/Fir" 或 "Cottonwood/Willow" 的行
filtered_dataset = dataset[dataset["Cover_Type"].isin(["Spruce/Fir", "Cottonwood/Willow"])]
正如你所见,云杉/冷杉覆盖面积比杨树/柳树覆盖面积更常见:
统计覆盖类型数量:
filtered_dataset["Cover_Type"].value_counts():此方法用于计算 filtered_dataset 中 “Cover_Type” 列每个唯一值的出现次数。结果将返回一个包含每种覆盖类型及其对应数量的 Series。
# 统计过滤后数据集中每种覆盖类型的数量
cover_type_counts = filtered_dataset["Cover_Type"].value_counts()
Cover_Type Spruce/Fir 211840 Cottonwood/Willow 2747 Name: count, dtype: int64
我们训练了一种流行的异常检测决策森林算法,称为隔离森林算法。
异常检测模型
创建模型:
ydf.IsolationForestLearner(features=features):使用 Yggdrasil 决策森林库中的 IsolationForestLearner 类来创建一个孤立森林(Isolation Forest)模型。该模型专门用于异常检测,features 参数指定了模型将使用的特征。
训练模型:
.train(filtered_dataset):调用 train 方法,使用 filtered_dataset 进行模型训练。该方法将数据集中的特征用于训练模型,以识别数据中的异常值。
进行预测:
model.predict(filtered_dataset):使用训练好的孤立森林模型对 filtered_dataset 进行预测。该方法将返回一个数组,包含每个数据点的预测结果,通常为 1(正常)或 -1(异常)。
显示预测结果:
predictions[:5]:提取并显示预测结果数组中的前五个元素,以便快速查看模型对前五个数据点的预测。
然后,我们可以生成“预测”,即异常分数。
# 创建并训练异常检测模型
model = ydf.IsolationForestLearner(features=features).train(filtered_dataset)
# 使用训练好的模型对过滤后的数据集进行预测
predictions = model.predict(filtered_dataset)
# 显示前五个预测结果
predictions[:5]
Train model on 214587 examples Model trained in 0:00:00.074241array([0.57844853, 0.609949 , 0.5433627 , 0.6099571 , 0.48067462], dtype=float32)
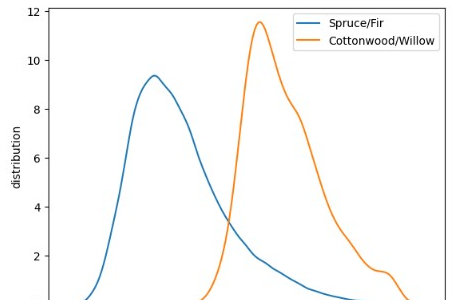
接下来,我们绘制了模型异常分数分布图,针对云杉/冷杉和棉白杨/柳树覆盖。我们发现这两个分布是“分离”的,这表明模型能够区分这两种覆盖。
注意:由于棉白杨/柳树覆盖较少,两种分布分别进行归一化。否则,棉白杨/柳树的分布将显得平坦。
绘制核密度估计图:
sns.kdeplot(...):使用 Seaborn 库的 kdeplot 方法绘制核密度估计(KDE)图。该图用于显示不同覆盖类型(”Spruce/Fir” 和 “Cottonwood/Willow”)的预测异常分数的分布。
predictions[filtered_dataset["Cover_Type"] == "Spruce/Fir"]:选择覆盖类型为 “Spruce/Fir” 的预测结果。
predictions[filtered_dataset["Cover_Type"] == "Cottonwood/Willow"]:选择覆盖类型为 “Cottonwood/Willow” 的预测结果。
设置坐标轴标签:
plt.xlabel(...) 和 plt.ylabel(...):分别设置 x 轴和 y 轴的标签,以描述图表的内容。
显示图例:
plt.legend():显示图例,以便区分不同覆盖类型的分布曲线。
# 绘制 "Spruce/Fir" 和 "Cottonwood/Willow" 的预测异常分数的核密度估计图
sns.kdeplot(predictions[filtered_dataset["Cover_Type"] == "Spruce/Fir"], label="Spruce/Fir")
sns.kdeplot(predictions[filtered_dataset["Cover_Type"] == "Cottonwood/Willow"], label="Cottonwood/Willow")
# 设置 x 轴和 y 轴标签
plt.xlabel("predicted anomaly score") # x 轴标签为 "预测异常分数"
plt.ylabel("distribution") # y 轴标签为 "分布"
# 显示图例
plt.legend()
AUC 是用于评估分类模型的指标。它也可以用来量化任何信号在区分两个不同类别时的判别能力。在异常检测的背景下,我们可以使用 AUC 来量化我们的异常检测模型能够隔离少数类的能力。
覆盖类型信息未用于训练模型,且数据集被认为是静态的(即,覆盖类型不会随时间变化)。因此,我们不需要在训练和测试之间分割数据集,而是将所有数据都用于训练模型并使用 AUC 进行评估。
计算 ROC AUC 分数:
filtered_dataset["Cover_Type"] == "Cottonwood/Willow":生成一个布尔数组,指示每个数据点是否属于 “Cottonwood/Willow” 类别。
metrics.roc_auc_score(...):使用 sklearn.metrics 中的 roc_auc_score 方法计算 ROC AUC 分数。这个分数用于评估模型的性能,尤其是在二分类问题中。AUC 值在 0 到 1 之间,值越高表示模型的性能越好。
# 计算 "Cottonwood/Willow" 的 ROC AUC 分数
roc_auc = metrics.roc_auc_score(filtered_dataset["Cover_Type"] == "Cottonwood/Willow", predictions)
输出结果:
运行这段代码后,roc_auc 将包含 “Cottonwood/Willow” 类别的 ROC AUC 分数。例如,如果得到的分数为 0.85,表示模型在区分 “Cottonwood/Willow” 和其他类别方面表现良好。
0.9427246186652949
高 AUC 确认了模型能够很好地分离两种覆盖类型。
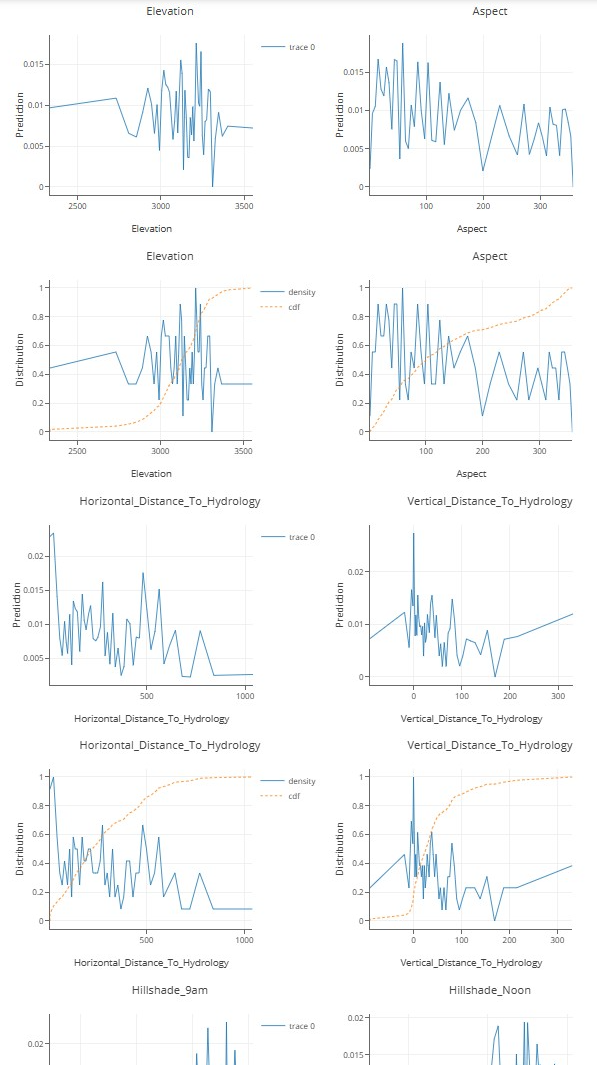
我们还可以分析模型来理解它:例如,我们在海拔的局部依赖图中看到,“正常”覆盖范围大约在 2900 米到 3300 米的海拔。通过查看其他属性,还可以得出其他类似的结论。
分析模型:
model.analyze(filtered_dataset, sampling=0.001):调用模型的 analyze 方法,对 filtered_dataset 进行分析。此方法通常用于评估模型的特征重要性、异常值检测结果等。
sampling=0.001:指定采样比例为 0.001,表示从数据集中随机抽取 0.1% 的数据进行分析。较小的采样比例可能会导致结果不够稳定或准确,因此注释中提到可以使用更大的采样比例来获得更好的分析结果。
输出结果:
运行这段代码后,模型将输出分析结果,可能包括特征重要性、异常值的分布等信息。这些结果可以帮助你理解模型的行为和性能。
# 使用指定的采样比例对过滤后的数据集进行分析
model.analyze(filtered_dataset, sampling=0.001) # 使用更大的采样比例以获得更好的结果
局部依赖图
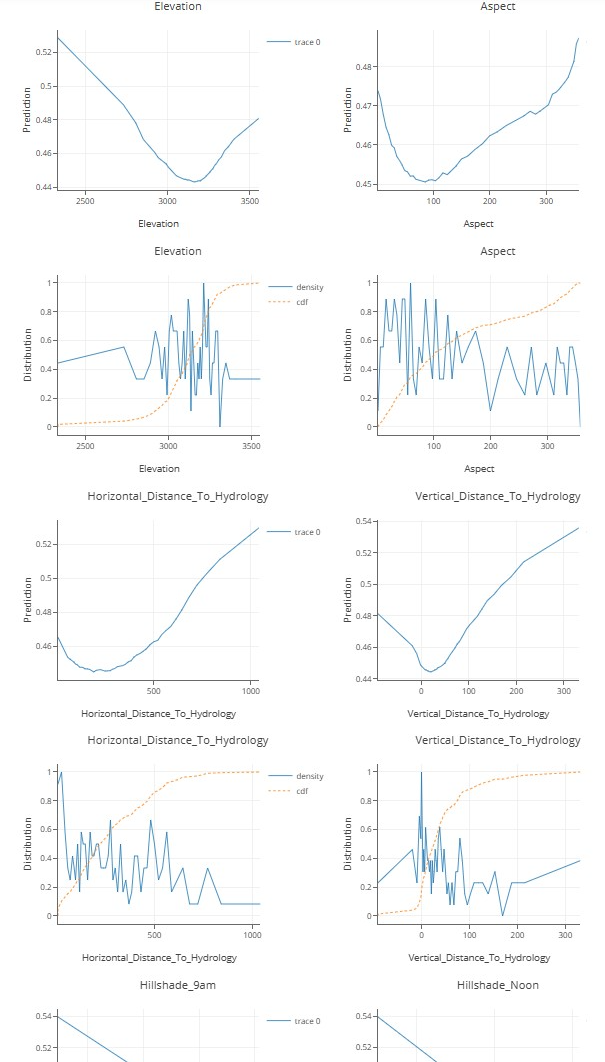
条件期望图
我们还可以解释单个模型的预测。例如,让我们选择第一个棉白杨/柳树示例并生成一个预测:
筛选样本:
filtered_dataset[filtered_dataset["Cover_Type"] == "Cottonwood/Willow"]:从 filtered_dataset 中筛选出所有覆盖类型为 “Cottonwood/Willow” 的数据点。
[:1]:从筛选出的数据中取出第一个样本。
显示样本:
first_willow_example:此变量将包含第一个 “Cottonwood/Willow” 类型的样本数据。
# 获取第一个 "Cottonwood/Willow" 类型的样本
first_willow_example = filtered_dataset[filtered_dataset["Cover_Type"] == "Cottonwood/Willow"][:1]
# 显示该样本
first_willow_example
| Elevation 海拔 | Aspect 方面 | Slope 斜率 | Horizontal_Distance_To_Hydrology 水文距离(水平) |
Vertical_Distance_To_Hydrology 垂直距离至水文 |
Horizontal_Distance_To_Roadways 到道路的水平距离 |
Hillshade_9am 阴影_上午 9 点 | Hillshade_Noon 中午阴影 | Hillshade_3pm 下午 3 点阴影 | Horizontal_Distance_To_Fire_Points 到火点的水平距离 |
Cover_Type 覆盖类型 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1988 | 2000 | 318 | 7 | 30 | 4 | 108 | 201 | 234 | 172 | 268 | Cottonwood/Willow 杉木/柳树 |
进行预测:
model.predict(first_willow_example):调用模型的 predict 方法,对 first_willow_example(第一个 “Cottonwood/Willow” 类型的样本)进行预测。该方法将返回模型对于该样本的预测结果。
显示预测结果:
predicted_result:此变量将包含模型对该样本的预测结果。
# 使用模型对第一个 "Cottonwood/Willow" 类型的样本进行预测
predicted_result = model.predict(first_willow_example)
# 显示预测结果
predicted_result
array([0.5474113], dtype=float32)
现在,让我们看看模型预测会如何随着这个示例的特征值而变化:
我们看到 2000 米高的例子是不常见的,并解释了一些高预测值的原因。另一方面,例子中的“坡向”和“坡度”相对正常。
分析预测:
model.analyze_prediction(first_willow_example):调用模型的 analyze_prediction 方法,对 first_willow_example(第一个 “Cottonwood/Willow” 类型的样本)的预测结果进行分析。此方法通常用于评估模型的预测可信度、特征重要性等。
显示分析结果:
analysis_result:此变量将包含模型对该样本预测的分析结果。
# 分析模型对第一个 "Cottonwood/Willow" 类型样本的预测
analysis_result = model.analyze_prediction(first_willow_example)
# 显示分析结果
analysis_result
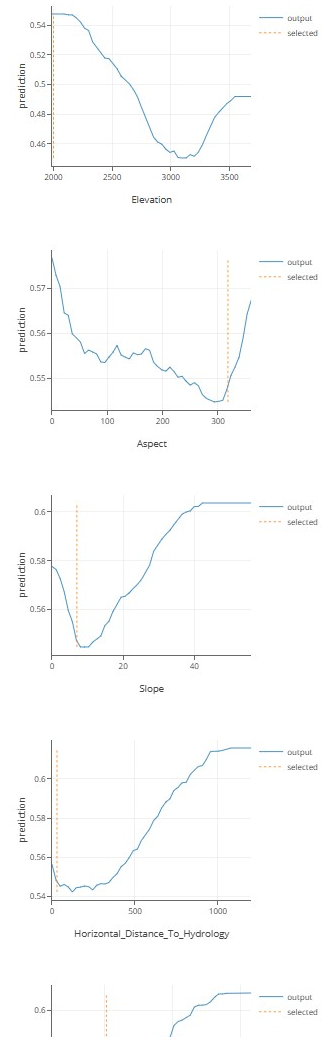
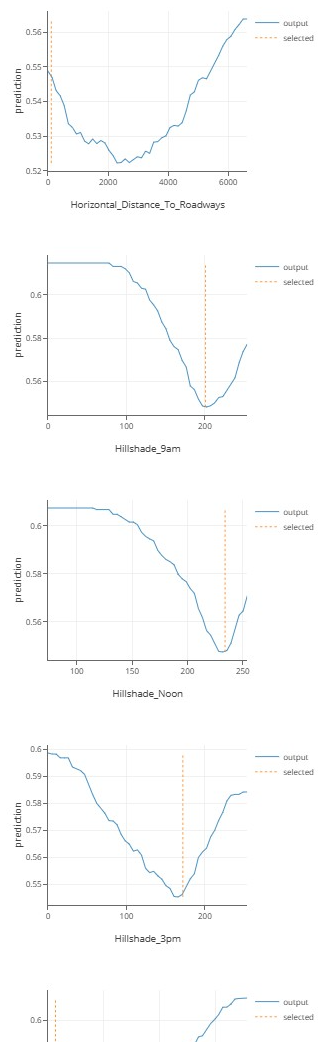
列出所有决策森林算法,我们的隔离森林模型定义了示例之间的隐式距离。这个距离可以用来聚类示例或进行可解释映射。
让我们计算每对示例之间的距离。为了使代码运行得更快,我们只选择前 10000 个示例。
计算距离:
model.distance(filtered_dataset[:10000]):调用模型的 distance 方法,计算前 10,000 个样本与模型的距离。这个距离通常用于评估样本与模型的相似度或异常程度。
使用更多的样本可以提高结果的准确性和代表性。
显示距离矩阵:
distances[:4, :4]:提取并显示距离矩阵的前 4 行和前 4 列,以便快速查看数据。
输出结果:
# 计算模型对前 10000 个样本的距离
distances = model.distance(filtered_dataset[:10000]) # 使用更多示例以获得更好的结果
# 显示前 4 行和前 4 列的距离矩阵
distances[:4, :4]
array([[0. , 0.86 , 0.6766667, 0.85 ],
[0.86 , 0. , 0.9066667, 0.31 ],
[0.6766667, 0.9066667, 0. , 0.8833333],
[0.85 , 0.31 , 0.8833333, 0. ]], dtype=float32)
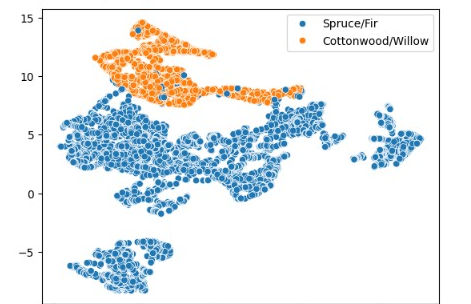
我们可以使用 UMAP(或任何其他流形学习算法,如 T-SNE)将示例投影到 2D 图中。.
请注意,尽管模型从未见过它们,覆盖类型仍然很好地分离。
降维处理:
umap.UMAP(n_components=2, n_neighbors=10, metric="precomputed"):创建一个 UMAP 对象,设置降维到 2 个维度,使用 10 个邻居,并且距离是预计算的(即使用已经计算好的距离矩阵)。
.fit_transform(distances):对距离矩阵进行降维处理,生成二维表示 manifold。
绘制散点图:
sns.scatterplot(...):使用 Seaborn 绘制散点图,x=manifold[:, 0] 和 y=manifold[:, 1] 分别表示降维后的 x 和 y 轴坐标。
hue=filtered_dataset["Cover_Type"][:manifold.shape[0]]:根据样本的覆盖类型为散点图添加颜色区分。
显示图例:
plt.legend():添加图例以标识不同的覆盖类型。
显示图形:
plt.show():显示绘制的散点图。
import umap
import seaborn as sns
import matplotlib.pyplot as plt
# 使用 UMAP 降维,将距离矩阵转换为 2D 表示
manifold = umap.UMAP(n_components=2, n_neighbors=10, metric="precomputed").fit_transform(distances)
# 绘制散点图
sns.scatterplot(x=manifold[:, 0],
y=manifold[:, 1],
hue=filtered_dataset["Cover_Type"][:manifold.shape[0]])
# 显示图例
plt.legend()
plt.show()
/usr/local/google/home/gbm/my_venv/lib/python3.11/site-packages/umap/umap_.py:1858: UserWarning: using precomputed metric; inverse_transform will be unavailable<matplotlib.legend.Legend at 0x7faa84413490>
























暂无评论内容