
在当今数据驱动的世界中,组织越来越多地利用机器学习 (ML) 来获取洞察、提高运营效率并推动创新。Google Cloud 的 Vertex AI 提供了一个强大而全面的平台,用于构建、部署和管理机器学习模型。
本博客探讨了 Vertex AI 作为端到端 ML 解决方案的功能,并从Google Cloud GenAI MLOps Blueprint中汲取了见解。
了解 Vertex AI
Vertex AI 是一个统一的机器学习平台,提供简化机器学习工作流程的工具,涵盖从数据准备、模型训练到部署和监控的各个环节。它旨在简化机器学习的复杂性,使数据科学家、机器学习工程师和开发者能够专注于构建创新解决方案,而非管理基础架构。
Vertex AI 的主要功能
统一体验
Vertex AI 集成了多种 Google Cloud 服务,在机器学习生命周期的不同阶段提供无缝衔接的体验。用户可以在单一界面内管理数据集、训练模型并部署解决方案。
可扩展基础设施
借助 Google Cloud 的强大功能,Vertex AI 可以根据项目需求扩展资源。用户可以利用强大的 GPU 和 TPU 来加速模型训练和推理,从而高效地处理大型数据集。
AutoML
Vertex AI 包含 AutoML 功能,可自动执行模型训练过程。用户只需极少的代码即可构建高质量的模型,即使没有丰富的 ML 专业知识,也能轻松上手。
MLOps 集成
Vertex AI 支持 MLOps 实践,允许组织实施机器学习模型的持续集成、持续部署和监控的最佳实践。
互操作性
Vertex AI 支持 TensorFlow、PyTorch 和 scikit-learn 等热门机器学习框架。这种灵活性使团队能够充分利用现有的专业知识和工具,同时与 Vertex AI 环境无缝集成。
Vertex AI 的机器学习工作流
Vertex AI 中的 ML 工作流程可以分为几个阶段,每个阶段对于开发成功的 ML 解决方案都至关重要。
数据准备
数据是任何机器学习项目的支柱。Vertex AI 提供强大的数据提取、清理和转换工具。用户可以连接到各种数据源,包括 BigQuery、Cloud Storage 和外部数据库,以访问和准备数据集。
模型训练
数据准备就绪后,下一步就是模型训练。Vertex AI 提供多种选择:
**自定义训练:**用户可以使用自己喜欢的机器学习框架定义模型架构。该平台提供强大的资源,帮助用户有效地训练这些模型。
**AutoML:**对于那些追求简单性的人来说,Vertex AI 的 AutoML 功能可以根据提供的数据自动构建和调整模型,从而减少模型开发所需的时间和精力。
模型评估
训练结束后,评估模型的性能至关重要。Vertex AI 提供内置评估指标,允许用户评估模型准确率、精确率、召回率和其他关键性能指标。这些反馈对于部署前进行必要的调整至关重要。
部署
部署模型以供生产使用是至关重要的阶段。Vertex AI 允许用户将模型部署为 REST API,从而实现实时预测。该平台支持在线和批量预测,可满足各种应用需求。
监控和维护
Vertex AI 的模型监控功能可确保持续的性能跟踪和异常检测,以优化生产中的机器学习模型。
让我们更详细地探讨这个问题。
在构建专业级机器学习解决方案时,上述步骤可作为整个流程的指南。现在,我们将讨论为确保解决方案的安全性和效率而需要考虑的最佳实践。
企业生成式人工智能和机器学习蓝图概述
企业生成式 AI 和 ML 蓝图提供了一个全面的框架,包括带有 Terraform 配置的 GitHub 存储库、Jupyter 笔记本、Vertex AI Pipelines 定义、Cloud Composer DAG 和用于部署的脚本。
集成 MLOps 以实现有效的模型训练和管理
企业生成式 AI 和 ML 蓝图采用分层方法支持模型训练,并设计为通过 MLOps 工作流进行部署和管理。下图展示了 MLOps 层与环境中其他层的集成。

该图涵盖以下元素:
**Google Cloud Infrastructure:**提供内置安全功能,如静态加密和传输加密,以及计算和存储服务等基本组件。
**企业基础:**提供一套基本资源,包括身份管理、网络、日志记录、监控和部署工具,从而实现无缝采用 Google Cloud 来处理 AI 工作负载。
**数据层:**开发堆栈中的可选组件,提供数据提取、存储、访问控制、治理、监控和共享等功能。
**生成式人工智能和机器学习层:**支持模型的开发和部署。它专为初始数据探索、实验、模型训练、服务和监控等任务而设计。
**CI/CD:**提供用于自动化基础设施配置、配置、管理以及工作流和软件部署的工具。这些工具可确保部署的一致性、可靠性和可追溯性,减少人工错误并加快开发周期。
直接利用数据创建模型
企业生成式 AI 和 ML 蓝图支持直接与数据互动,让您可以在交互式(开发)环境中创建模型,然后将其转换为操作(生产或非生产)环境。
使用 Vertex AI Workbench 开发 ML 模型
在交互式环境中,您可以使用 Vertex AI Workbench(Google 管理的 Jupyter Notebook 服务)开发机器学习模型。在这里,您可以实现数据提取、转换和模型调整,然后将这些功能推广到运营环境。
作战环境中的系统模型构建与测试
在操作(非生产)环境中,您可以利用管道以可重复和可控的方式系统地构建和测试您的模型。
一旦您对模型的性能充满信心,就可以将其部署到运营(生产)环境中。下图展示了交互式环境和运营环境的各个组件。
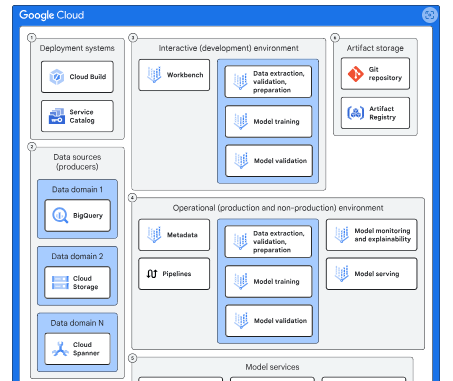
该图包括以下组件:
部署系统:
Service Catalog 和 Cloud Build 等服务有助于在交互式环境中部署 Google Cloud 资源。Cloud Build 还负责将这些资源和模型构建工作流部署到运营环境中。
数据来源:
BigQuery、Cloud Storage、Spanner 和 AlloyDB for PostgreSQL 等服务可托管您的数据。蓝图包含 BigQuery 和 Cloud Storage 中可用的示例数据集。
交互式环境:
您可以直接处理数据、试验模型并为操作环境创建管道的空间。
操作环境
该区域旨在以可重复的方式构建和测试模型,以便部署到生产中。
**模型服务:**以下服务支持各种 MLOps 活动:
**Vertex AI Feature Store:**为您的模型提供特征数据。
**Model Garden:**提供 ML 模型库,包括 Google 的模型和精选的开源选项。
**Vertex AI 模型注册表:**管理您的 ML 模型的生命周期。
**工件存储:**这些服务负责存储模型开发和流程中使用的代码和容器。它们包括:
**工件注册表:**存储操作环境中管道使用的容器,以管理模型开发的不同阶段。
**Git 存储库:**维护模型开发所涉及的各个组件的代码库。
平台角色:
部署蓝图时,您需要创建四个用户组:MLOps 工程师、DevOps 工程师、数据科学家和数据工程师。每个组都有特定的职责:
MLOps工程师组为服务目录开发Terraform模板,提供适用于多种模型的模板。
DevOps工程师组审查并批准 MLOps 团队创建的 Terraform 模板。
数据科学家组负责开发模型、管道以及这些管道所使用的容器,通常每个模型都有一个专门的团队。
数据工程师组的 任务是批准数据科学组创建的工件。
组织结构
该蓝图以企业基础蓝图的组织结构为基础,用于部署 AI 和 ML 工作负载。下图展示了已添加到基础蓝图以支持 AI 和 ML 工作负载的项目。

联网
该蓝图利用企业基础蓝图中建立的共享 VPC 网络。在交互式(开发)环境中,Vertex AI Workbench 笔记本部署在服务项目内,允许本地用户通过共享 VPC 网络中的私有 IP 地址空间访问这些项目。
本地用户可以通过 Private Service Connect 连接到 Google Cloud API(例如 Cloud Storage)。每个共享 VPC 网络(开发、非生产和生产)都配置了单独的 Private Service Connect 端点。
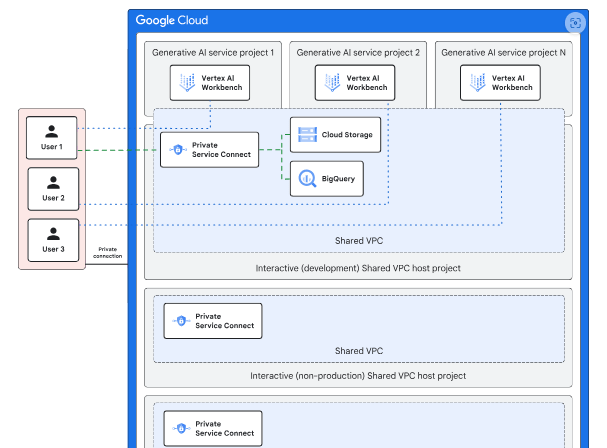
运营环境由非生产环境和生产环境组成,并设置了两个不同的共享 VPC 网络,本地资源可以通过私有 IP 地址访问。交互环境和运营环境均使用 VPC 服务控制机制进行安全保护。
云日志
此蓝图使用企业基础蓝图提供的云日志功能。
云监控
为了监控自定义训练作业,蓝图包含一个仪表板,可让您监控以下指标:
每个训练节点的CPU利用率
每个训练节点的内存利用率
网络使用情况
如果自定义训练作业失败,蓝图会利用 Cloud Monitoring 发送电子邮件提醒,通知您问题所在。对于通过 Vertex AI 端点部署的监控模型,蓝图包含一个信息中心,其中显示以下指标:
性能指标:
每秒预测次数
模型延迟
资源使用情况:
CPU 使用率
内存使用情况
运营
交互式环境
为了让您能够探索数据和开发模型,同时遵守组织的安全标准,交互式环境提供了一组受控的允许操作。您可以使用以下方法之一部署 Google Cloud 资源:
通过服务目录部署资源,服务目录通过自动化预先配置了资源模板。
使用 Vertex AI Workbench 笔记本创建代码工件并将其提交到 Git 存储库。
下图描述了交互式环境。

部署资源:
数据科学家使用服务目录部署 Vertex AI Workbench 笔记本,它是使用 Google Cloud 资源的主要界面。
源数据管理:
源数据单独存储,由数据所有者管理,对于数据科学家来说是只读的,他们可以将数据传输到交互式环境中,但不能将其传出。
数据存储:
BigQuery 和 Cloud Storage 分别处理结构化和非结构化数据,而 Feature Store 为模型训练提供低延迟访问。
模型训练:
数据科学家使用 Vertex AI 自定义训练作业训练模型并执行超参数调整。
模型评估:
Vertex AI Experiments 和 TensorBoard 能够跟踪和比较模型性能,而 Vertex AI 评估则使用训练和验证数据集来验证模型。
运营整合:
数据科学家使用 Cloud Build 构建容器,将其存储在 Artifact Registry 中,并在操作环境中的管道中使用它们。
运行环境
操作环境包含 Git 存储库和管道,涵盖企业基础蓝图的生产和非生产设置。
在非生产环境中,数据科学家选择在交互式环境中开发的管道,运行它,评估结果,并决定将哪个模型推广到生产环境。
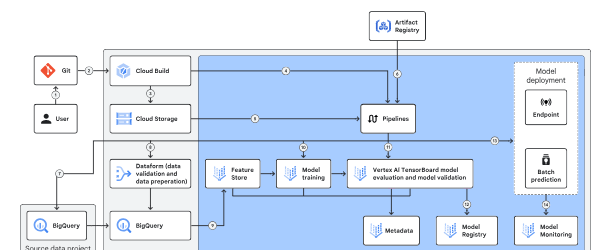
典型的操作流程包括以下步骤:
数据科学家将开发分支合并到部署分支,这将触发 Cloud Build 流水线,根据所使用的编排器将 DAG 或 Python 文件移动到 Cloud Storage。
然后,管道从 Artifact Registry 中提取一个容器以促进数据传输,并使用 Vertex AI 自定义训练和评估为模型训练做好准备。
最后,将验证后的模型导入模型注册表进行预测,同时 Vertex AI 模型监控会跟踪其在生产环境中的性能。
部署
该蓝图采用一系列 Cloud Build 流水线来配置创建生成式 AI 和 ML 模型所需的基础设施、运营环境和容器。具体流水线和已配置的资源如下:
**基础设施管道:**作为企业基础蓝图的一部分,该管道为交互和操作环境提供 Google Cloud 资源。
**交互式管道:**此管道在交互式环境中运行,将 Terraform 模板从 Git 代码库复制到服务目录的云存储桶中。它由与主分支合并的拉取请求触发。
**容器流水线:**包含 Cloud Build 流水线,用于为运营流水线创建不可变的容器镜像。这些镜像可确保跨环境的一致部署,并存储在 Artifact Registry 中,供运营配置文件引用。
操作管道: 此管道是操作环境的一部分,它复制 Cloud Composer 或 Vertex AI Pipelines 的 DAG 以构建、测试和部署模型。
服务目录
服务目录 (Service Catalog) 允许开发者和云管理员向企业内部用户提供其解决方案。Terraform 模块通过 Cloud Build CI/CD 流水线构建并作为工件发布到 Cloud Storage 存储桶。
模块复制完成后,开发者可以在Service Catalog Admin页面创建Terraform解决方案,并添加到Service Catalog中,共享给交互式环境项目进行资源部署。
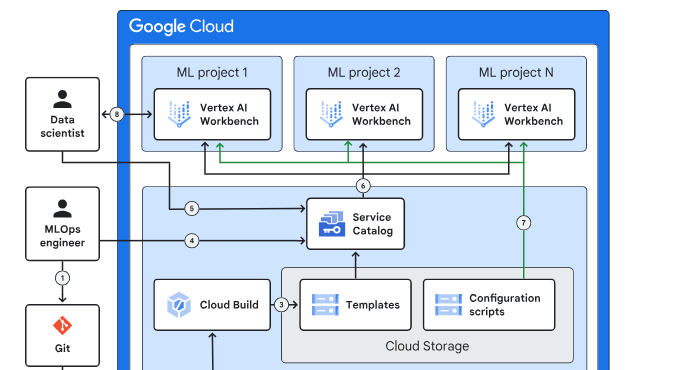
安全控制
企业生成式 AI 和 ML 蓝图采用分层纵深防御安全模型,该模型利用默认的 Google Cloud 功能、Google Cloud 服务和通过企业基础蓝图配置的安全功能。
下图说明了蓝图内的各个安全控制层。

以下是要点的简明版本:
**界面:**提供数据科学家控制的与蓝图交互的访问权限。
**部署:**利用管道进行基础设施部署、容器构建和模型创建,确保可审计性、可追溯性和可重复性。
**网络:**在蓝图资源的 API 层和 IP 层实施数据泄露保护。
**访问管理:**管理资源访问以防止未经授权的使用。
**加密:**支持对加密密钥和秘密的控制,使用默认的静态加密和传输中加密保护数据。
**侦探:**检测错误配置和恶意活动。
**预防性:**对基础设施部署进行控制和限制。
结论
总而言之,本博客概述了使用 Vertex AI 实现端到端 MLOps 的全面框架,并强调了各种 Google Cloud 资源和服务的集成。通过利用结构化的流水线、强大的安全措施和有效的访问管理,组织可以简化生成式 AI 和 ML 模型的开发、部署和监控。
这种分层方法不仅提高了运营效率,而且还确保了数据保护和合规性,使数据科学家能够在维护安全和受控环境的同时进行创新。



















暂无评论内容