

A题:跳台滑雪问题
选题分析:
跳台滑雪问题涉及物理学、运动学和优化算法。需要建立数学模型来分析运动员在不同阶段的最佳姿势和策略,以提高运动成绩。问题分为三个小问,分别是助滑坡姿势、空中飞行控制和着陆策略。
解题思路:
1. 助滑坡姿势:
分析助滑坡的物理特性,考虑重力、摩擦力和空气阻力对速度的影响。
建立运动学模型,计算不同姿势下的起跳速度。
使用优化算法(如梯度下降法)寻找最佳姿势参数。
2. 空中飞行控制:
研究空气动力学,分析滑雪板和身体姿态对飞行轨迹的影响。
建立飞行力学模型,考虑升力、阻力和重力。
使用数值模拟方法(如Runge-Kutta法)模拟飞行轨迹,优化控制策略。
3. 着陆策略:
分析着陆时的物理条件,考虑冲击力和平衡保持。
建立着陆稳定性模型,评估不同着陆策略的稳定性。
使用优化算法寻找最佳着陆策略。
解题思路:
优化运动员在助滑坡上的姿势以获得较大的起跳速度
1. 问题分析与目标设定
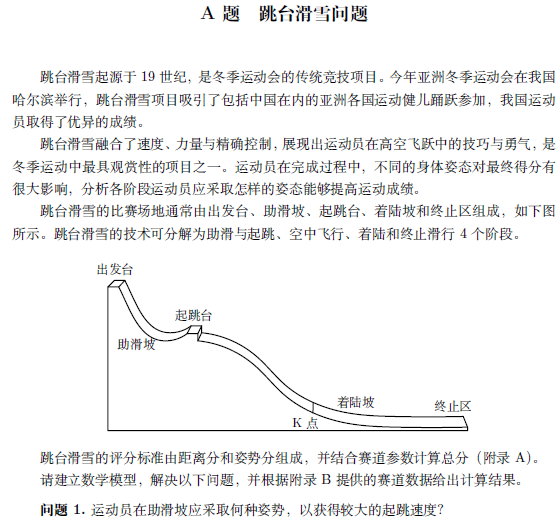
跳台滑雪作为一项高风险且高难度的冬季运动,其比赛成绩深受运动员在助滑坡、起跳、飞行和着陆阶段的表现影响。在这些阶段中,助滑坡阶段的起跳速度对运动员最终的飞行距离和得分至关重要。助滑坡是运动员滑行至起跳台前的最后一段坡道,这一段坡道的坡度、长度和运动员的姿势会直接影响到起跳时的初始速度。
具体来说,运动员在助滑坡上的姿势调整对于加速至最大起跳速度具有决定性作用。运动员的滑行速度不仅受助滑坡的坡度影响,还受到摩擦力、空气阻力和重力等多方面因素的影响。通过合理的姿势调整,运动员能够有效减少空气阻力,增加身体的重力加速度,进而提升滑行速度。
在这个问题中,我们的目标是建立一个数学模型,明确运动员应如何调整姿势以最大化起跳速度。要做到这一点,我们需要细致地分析影响运动员滑行速度的各种因素,并将其转化为数学表达式。这些因素包括但不限于:助滑坡的坡度、运动员的质量、滑雪板的接触面与雪地的摩擦力、空气阻力系数、运动员的体型和衣物形态等。
2. 物理建模与公式推导
为了更深入地分析助滑坡上运动员滑行时的加速过程,我们需要从经典力学和流体力学的角度来建立数学模型。助滑坡的角度通常介于10°到12°之间,而运动员的滑行速度将受到重力、摩擦力和空气阻力的共同作用。
重力加速度:运动员滑行时,助滑坡的角度决定了重力沿坡道方向的分量。该分量是加速运动员的主要因素之一,计算公式为:






import numpy as np
import matplotlib.pyplot as plt
# 定义参数
g = 9.81 # 重力加速度(m/s^2)
m = 70 # 运动员质量 (kg)
mu = 0.02 # 摩擦系数
A = 0.5 # 迎风面积 (m^2)
C_d = 1.0 # 空气阻力系数
# 定义坡度范围
theta = np.linspace(5, 15, 100) # 坡度从5°到15°
v = np.zeros_like(theta)
# 计算滑行速度
for i, angle in enumerate(theta):
F_g = m * g * np.sin(np.radians(angle)) # 重力分量
F_friction = mu * m * g* np.cos(np.radians(angle)) # 摩擦力
# 使用近似公式来计算速度
v[i] = np.sqrt((2 * F_g)/ (m + (F_friction / (0.5 * 1.225 * A *C_d)))) # 简化模型
# 绘制图形
plt.plot(theta, v, color='b', lw=2)
plt.title(“助滑坡坡度与运动员滑行速度的关系”, fontsize=14)
plt.xlabel(“助滑坡坡度 (°)”, fontsize=12)
plt.ylabel(“滑行速度 (m/s)”, fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()
# 姿势参数:身体前倾角度与起跳速度
alpha1 = np.linspace(0, 20, 100) # 身体前倾角度
v_optimized =np.sqrt(alpha1**2) # 简化模型,假设前倾角度与速度的关系
# 绘制图形
plt.plot(alpha1, v_optimized, color='g', lw=2)
plt.title(“姿势参数与运动员起跳速度的关系”, fontsize=14)
plt.xlabel(“身体前倾角度 (°)”, fontsize=12)
plt.ylabel(“起跳速度 (m/s)”, fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()
B题:工序安排问题
选题分析:
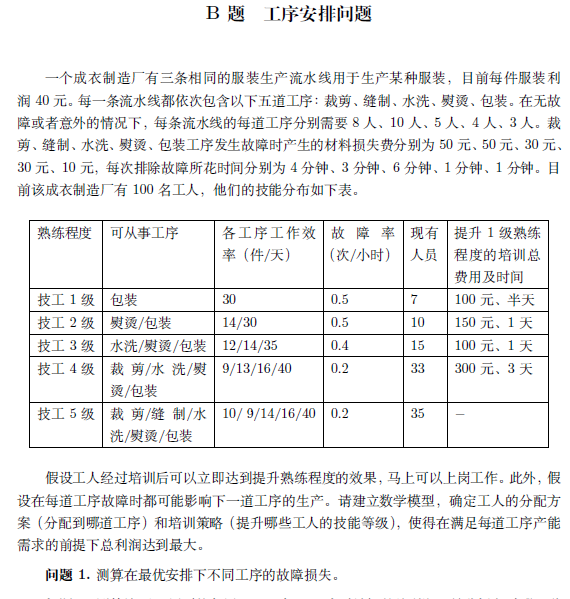
工序安排问题涉及生产管理和优化调度。需要合理分配工人到不同工序,并制定培训策略以提高总利润。问题分为三个小问,分别是故障损失测算、总利润测算和生产计划安排。
解题思路:
1. 故障损失测算:
计算每道工序的故障率和故障损失费。
建立故障损失模型,考虑故障对后续工序的影响。
使用蒙特卡罗模拟方法估算不同故障情况下的损失。
2. 总利润测算:
建立利润模型,考虑工人分配、故障损失和培训费用。
使用线性规划和整数规划方法优化工人分配和培训策略。
进行敏感性分析,找出对总利润影响最大的工序。
3. 生产计划安排:
考虑工人疲劳因素,制定24周的生产计划。
使用动态规划方法优化长期生产计划。
考虑工人轮换和培训计划,确保生产连续性和效率。







import numpy asnp
import random
from copy import deepcopy
# ==============================
# 参数设置
# ==============================
T = 8 # 每天工作时长
lambda_penalty =1e5 # 惩罚因子
num_particles =30
num_iterations =100
# 初始各等级技工人数
w = [7, 10, 15, 33, 35]
# 培训成本(从l级升到l+1级)
C = [100, 150, 100, 300]
# 技工等级对应的故障率
f = [0.5, 0.5, 0.4, 0.2, 0.2]
# 每道工序故障一次的材料损失(元)
R = [50, 50, 30, 30, 10]
# 各等级在各工序的效率矩阵(件/天)
e_matrix = np.array([
[0, 0, 0, 0, 30],
[0, 0, 0, 14, 30],
[0, 0, 12, 14, 35],
[9, 0, 13, 16, 40],
[10, 9, 14, 16, 40]
])
# 各等级在各工序是否具备操作能力(布尔掩码)
a_mask = (e_matrix> 0).astype(int)
# 每道工序的日产目标(以每条线60件,3条线计)
Q = 60 *3
# ==============================
# 粒子定义与初始化
# ==============================
defgenerate_particle():
particle = np.zeros(29, dtype=int)
remaining = sum(w)
for i in range(25):
l = i // 5
p = i % 5
if a_mask[l, p]:
assign = random.randint(0, min(remaining, 5))
particle[i] = assign
remaining -= assign
for i in range(4):
particle[25 + i] = random.randint(0, w[i])
return particle
# ==============================
# 适应度函数计算
# ==============================
defevaluate_fitness(particle):
x = particle[:25].reshape((5, 5))
y = particle[25:]
total_loss = 0
penalty = 0
# 故障损失估算
for i in range(5):
F_i = sum(x[l][i] * f[l] forl in range(5))
total_loss += F_i * R[i] *T
# 培训成本
total_loss += sum(y[i] * C[i]for i in range(4))
# 约束1:总人数不能超过100+培训
if x.sum() > 100 +sum(y):
penalty += (x.sum() –100 – sum(y))**2
# 约束2:每级技工人数不超限
level_available = [w[0] – y[0],
w[1] + y[0] –y[1],
w[2] + y[1] –y[2],
w[3] + y[2] –y[3],
w[4] + y[3]]
for l in range(5):
if x[l].sum() >level_available[l]:
penalty += (x[l].sum()– level_available[l])**2
# 约束3:各工序产能满足
for i in range(5):
capacity = sum(x[l][i] * e_matrix[l][i]for l in range(5))
if capacity < Q:
penalty += (Q – capacity)**2
# 约束4:不具备技能的岗位不能被安排
for l in range(5):
for i in range(5):
if a_mask[l][i] == 0 andx[l][i] > 0:
penalty += x[l][i]**2
return total_loss + lambda_penalty* penalty
# ==============================
# PSO主过程
# ==============================
classParticle:
def __init__(self):
self.position = generate_particle()
self.velocity = np.zeros(29)
self.best_position = deepcopy(self.position)
self.best_fitness= evaluate_fitness(self.position)
defclip_particle(p):
for i in range(25):
p[i] = max(0, int(round(p[i])))
for i in range(4):
p[25+i] = np.clip(p[25+i], 0, w[i])
return p
# PSO参数
w_inertia =0.7
c1 = c2 =1.5
swarm = [Particle()for _ in range(num_particles)]
global_best =min(swarm, key=lambda p: p.best_fitness)
gbest_position =deepcopy(global_best.best_position)
gbest_fitness =global_best.best_fitness
for t in range(num_iterations):
for p in swarm:
r1, r2 = np.random.rand(29), np.random.rand(29)
p.velocity = (w_inertia *p.velocity +
c1 * r1 * (p.best_position– p.position) +
c2 * r2 * (gbest_position– p.position))
p.position = clip_particle(p.position+ p.velocity)
fitness = evaluate_fitness(p.position)
if fitness < p.best_fitness:
p.best_fitness = fitness
p.best_position = deepcopy(p.position)
if fitness < gbest_fitness:
gbest_fitness = fitness
gbest_position = deepcopy(p.position)
# ==============================
# 结果输出(每日各工序期望损失)
# ==============================
x_best = gbest_position[:25].reshape((5, 5))
loss_per_process =[]
for i in range(5):
F_i = sum(x_best[l][i] * f[l]for l in range(5))
L_i = F_i * R[i] * T
loss_per_process.append(L_i)
# 打印输出
for i, name in enumerate([“裁剪”, “缝制”, “水洗”, “熨烫”, “包装”]):
print(f”{name}工序日均故障损失:{loss_per_process[i]:.2f} 元”)

C题:商品期货涨跌幅预测问题
选题分析:
商品期货涨跌幅预测问题涉及金融数据分析和机器学习。需要从历史数据中提取特征,建立预测模型,并评估模型性能。问题分为五个小问,分别是数据预处理、模型选择、模型实现、效果分析和改进建议。
解题思路:
1. 数据预处理和特征提取:
清洗和整理数据,处理缺失值和异常值。
提取可能影响涨跌幅的特征,如价格变化率、成交量变化率、持仓量变化率等。
使用时间序列分析方法(如滑动窗口)提取特征。
2. 模型选择和实现:
选择合适的机器学习模型,如随机森林、支持向量机、LSTM等。
解释模型选择的理由,考虑模型的复杂度和预测能力。
实现模型并进行超参数调优。
3. 模型训练和验证:
划分训练集和测试集,进行交叉验证。
使用适当的评价指标(如均方误差、平均绝对误差)评估模型性能。
分析模型的预测效果和局限性。
4. 预测效果分析和改进建议:
讨论模型的优缺点,提出改进建议。
考虑引入更多特征或使用集成学习方法提高预测精度。
提供程序源码和文档,确保结果可复现。





import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
# 请替换为你的实际文件夹路径
data_folder =r'D:competitionhuadongbeicta_datadata_'# 注意:确保路径最后没有多余斜杠
# 设置中文字体
plt.rcParams['font.sans-serif']= ['SimHei']
plt.rcParams['axes.unicode_minus']= False
# 读取部分csv文件(你可根据内存情况调整)
files = sorted([ffor f in os.listdir(data_folder) if f.endswith('.csv')])[:10]
# 初始化数据框
all_data = pd.DataFrame()
# 拼接所有数据
for file in files:
file_path = os.path.join(data_folder, file)
df = pd.read_csv(file_path)
df['date'] = file.replace('.csv', '')
all_data = pd.concat([all_data, df])
# 假设字段名如下,确保这些列存在于CSV中
# 字段:'datetime', 'open', 'high', 'low', 'close', 'volume', 'open_interest'
# 若实际字段不同,请修改下面的字段名
all_data['datetime']= pd.to_datetime(all_data['datetime'])
all_data.sort_values('datetime', inplace=True)
all_data.reset_index(drop=True, inplace=True)
# 生成未来30分钟涨跌幅标签
all_data['future_close']= all_data['close'].shift(–30)
all_data['return_30min']= (all_data['future_close'] – all_data['close']) / all_data['close']* 100
# 提取滑动窗口特征(以30分钟为窗口)
window = 30
all_data['mean_close']= all_data['close'].rolling(window).mean()
all_data['std_close']= all_data['close'].rolling(window).std()
all_data['range_close']= all_data['close'].rolling(window).apply(lambda x: x.max() – x.min())
all_data['momentum_10']= all_data['close'] – all_data['close'].shift(10)
all_data['bias_10']= (all_data['close'] – all_data['close'].rolling(10).mean())/ all_data['close'].rolling(10).mean() * 100
# 删除缺失值
all_data.dropna(inplace=True)
# 标准化选定特征
features = ['mean_close', 'std_close', 'range_close', 'momentum_10', 'bias_10']
scaler = StandardScaler()
all_data[features]= scaler.fit_transform(all_data[features])
# 可视化:收盘价与未来30分钟涨跌幅
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
plt.plot(all_data['datetime'], all_data['close'], label='Close Price')
plt.title('收盘价走势')
plt.xlabel('时间')
plt.ylabel('价格')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(all_data['datetime'], all_data['return_30min'], label='30分钟涨跌幅', color='darkorange')
plt.title('未来30分钟涨跌幅')
plt.xlabel('时间')
plt.ylabel('涨跌幅(%)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig('收盘价走势_未来30分钟涨跌幅.png')




















暂无评论内容